Comparative Analysis of Large Language Model Latency

Dylan Zuber
⸱
Software Engineer
May 13, 2024

In the digital era, where the efficiency of AI-driven applications hinges heavily on the performance of large language models (LLMs), understanding which model delivers the best latency is crucial for technology-driven companies. To this end, we conducted an extensive performance analysis using Langtrace, an open-source observability tool that plays a pivotal role in monitoring and improving LLM applications.Interested in other LLM studies? Check out our recent blog post testing GPT-4’s accuracy during high traffic.
Models Compared
For our evaluation, we selected four industry-leading language models:
Anthropic's Claude-3-Opus-20240229
OpenAI's GPT-4
Groq running LLaMA3-8B-8192
Cohere's Command-R-Plus
These models were tested under various token configurations to reflect common usage scenarios in real-world applications.
Testing Methodology

We employed the following testing approach:
10 Requests Per Model: Each model was subjected to 10 requests per input/output token pairing.
Check out the prompts: https://gist.github.com/dylanzuber-scale3/f4be5a3cde5e30f40dae4874d9ef8a78
Averaging Latencies: The latency for each request was recorded, and an average latency was calculated.
Langtrace Usage: All data was captured and stored using Langtrace. This tool was instrumental in collecting, tracing, and analyzing the metrics that informed our results.
The token configurations for the tests were as follows:
Scenario A: ~500 input tokens with a ~3,000-token output limit.
Scenario B: ~1,000 input tokens with a ~3,000-token output limit.
Scenario C: ~5,000 input tokens with a ~1,000-token output limit.
Performance Insights
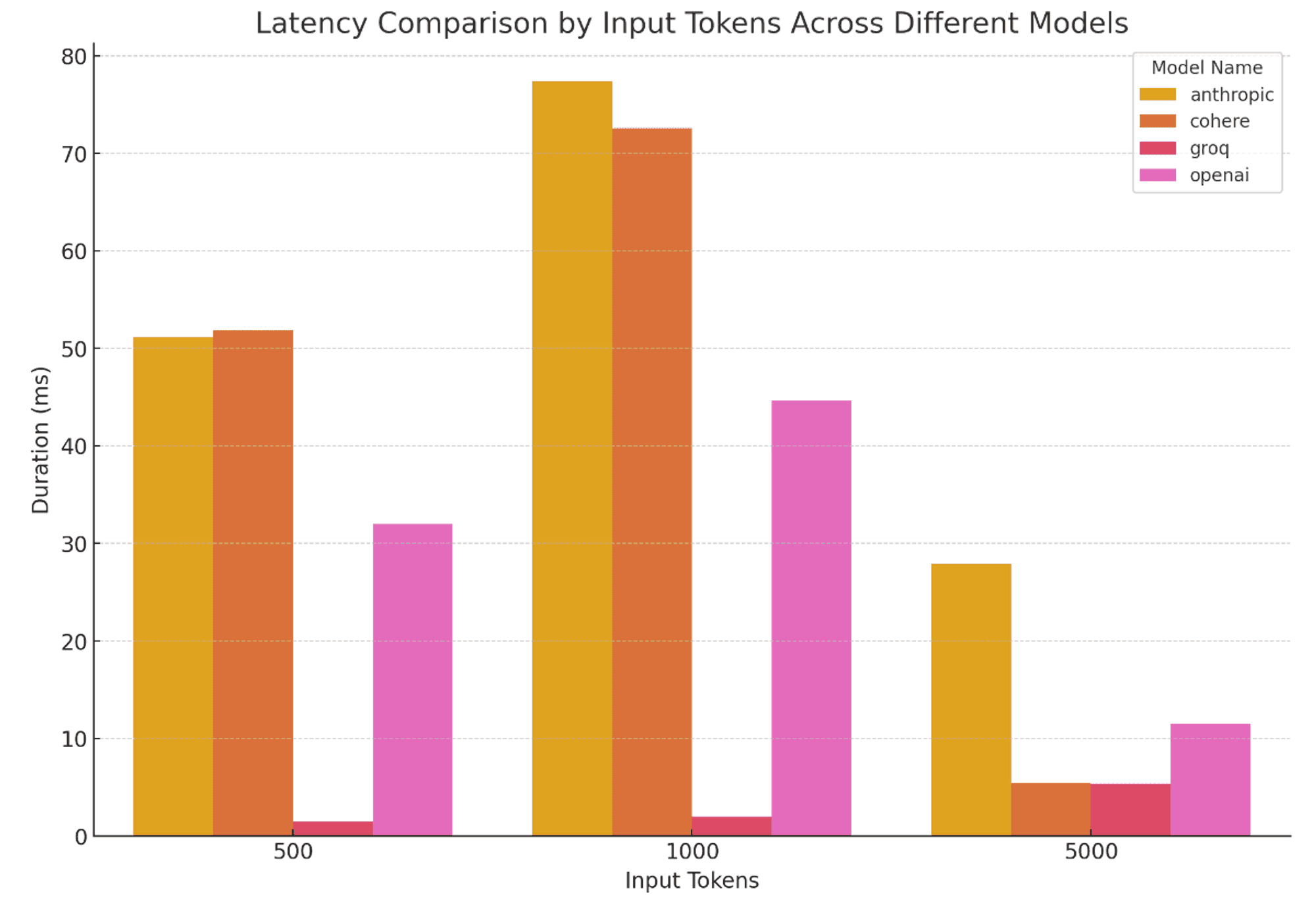
Here are the latency results from our detailed analysis:
Scenario A (500 Input Tokens, 3k Output Tokens):
Anthropic: 51.14 seconds
Cohere: 51.88 seconds
Groq: 1.46 seconds
OpenAI: 32.03 seconds
Scenario B (1k Input Tokens, 3k Output Tokens):
Anthropic: 77.41 seconds
Cohere: 72.57 seconds
Groq: 2.02 seconds
OpenAI: 44.65 seconds
Scenario C (5k Input Tokens, 3k Output Tokens):
Anthropic: 27.92 seconds
Cohere: 5.41 seconds
Groq: 5.35 seconds
OpenAI: 11.48 seconds
Analysis and Recommendations
Groq running Llama-3 excels in scenarios where efficiency is critical, offering the lowest latencies across all tests. It's the ideal choice for applications where speed is essential.
OpenAI's GPT-4 is the industry leader in accuracy known for its high accuracy however has higher latency compared to Groq. It's best suited for tasks where the quality of the output is more important than speed
Cohere’s Command R Plus is an efficient alternative to Groq for scenarios with higher input tokens and lower output tokens.
Conclusion
Choosing the right LLM for specific operational needs depends critically on understanding each model’s latency under various conditions. Langtrace has been indispensable in this evaluation, providing robust data collection and analysis to make informed decisions. With the introduction of our prompt comparison feature, users can now conduct similar tests using the prompt playground at Langtrace.ai. This tool allows you to test different prompts and compare responses, as well as directly measure the latencies of various models in real-time. These insights not only assist in selecting the appropriate model but also highlight the value of sophisticated tooling like Langtrace in optimizing LLM applications.
We'd love to hear your feedback on our LLM latency analysis! We invite you to join our community on Discord or reach out at support@langtrace.ai and share your experiences, insights, and suggestions. Together, we can continue to set new standards of observability in LLM development.
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
