Why You Need Evaluations in your LLM App and How Langtrace Can

Oluwadabira Akinwumi
⸱
Software Engineer
Jul 31, 2024

Since the release of ChatGPT by OpenAI, Large Language Models(LLM’s) have been all the rave. Numerous Large Language Models (LLMs) have since been launched. These models include advancements from both major tech companies and open-source communities. Notable examples are Anthropic’s Claude, Mistral, and Google’s Bard
As more companies integrate Large Language Models into their products and services, it becomes essential to evaluate the accuracy of these models' responses and refine prompts to achieve optimal results. This is where LLM evaluations come in. Langtrace makes it easy run LLM evaluations.
But why would I even need to run evaluations?
Let’s set the stage. We are an EdTech company building an AI chatbot to help students with their homework. There are a multitude of large language models we can choose to build our chatbot with. We also need to factor in cost of the models while also making sure our chatbot is accurate.
How can we choose the appropriate model? We can choose the correct model by running evaluations.
Running evaluations gives us the ability to benchmark the results of our chatbot against other models to test its accuracy
For the sake of this tutorial we are going to use OpenAI’s GPT 3.5-turbo model to build our chatbot. We will run an evaluation against Open AI’s GPT-4o model and compare results. Lets get started.
Lets go over how to run evaluations for our AI chatbot in Langtrace using python
All the code we use in this tutorial is available in this repository.
Steps
Firstly if you have not signed up for Langtrace, head over and create and account.
After you have signed up, create a new project and generate an api key. Make sure to keep that key you will need it for later.

Note: If you need to regenerate an api key for an already existing project. You can do so in the settings tab of your project. However your previous API key will no longer work.
Follow along to run evaluations on our AI chatbot
We need to Install the Langtrace python sdk and Inspect AI.
Make sure you add the LANGTRACE_API_KEY to your environment variables as shown below.
Initialize Langtrace in your project. Make sure to replace the YOUR_LANGTRACE_API_KEY placeholder with your actual API key which we got at the start of this article.

Run your AI chatbot
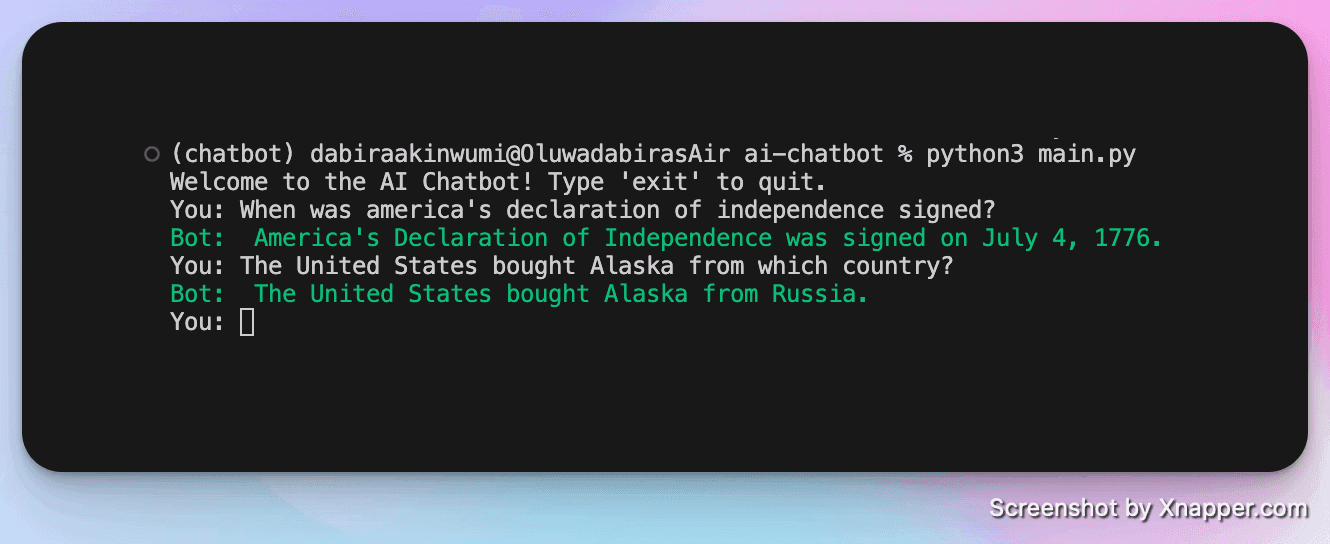
As you ask your bot questions you will be able to see the traces in Langtrace.

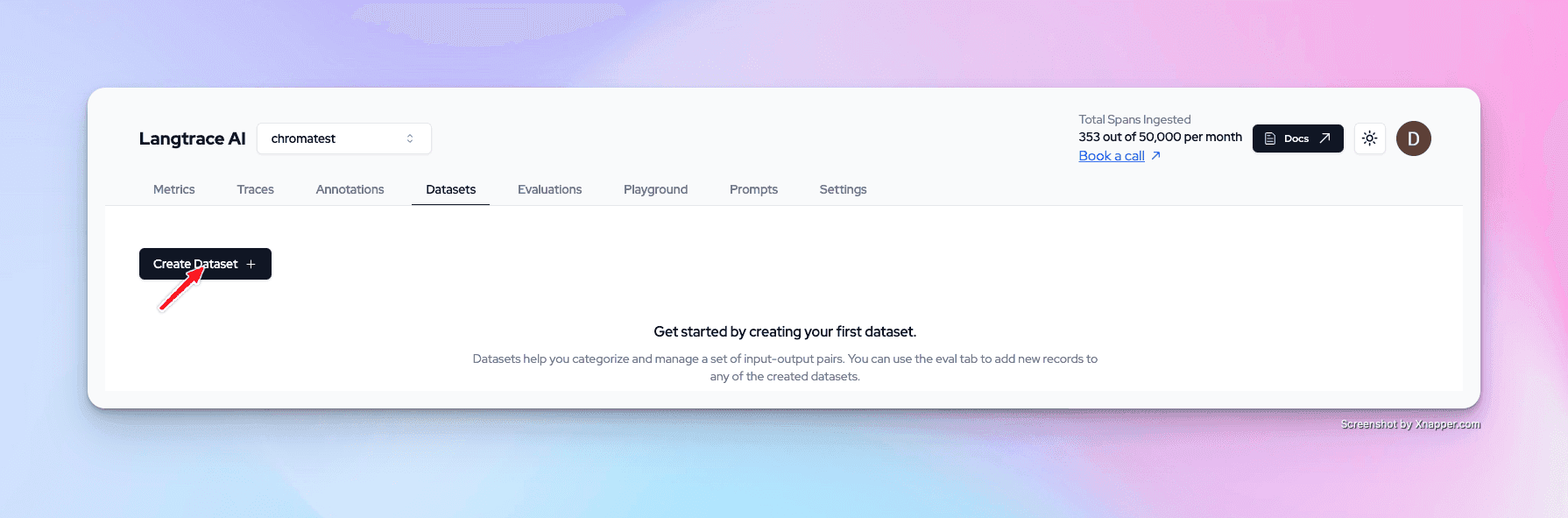
Create a dataset. After you create the dataset, copy the dataset ID. You will need it later

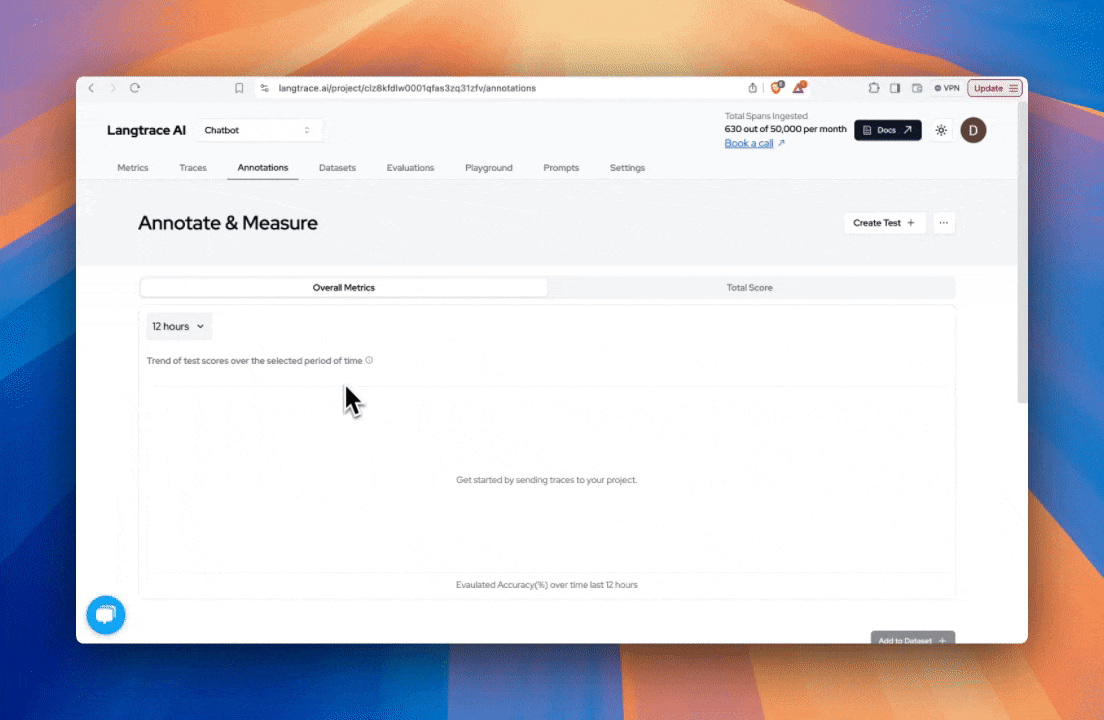
Head over to the annotations tab in your Langtrace Dashboard. Select your traces and add them to your newly created dataset.
Write an evaluation script to run your evaluations. Let’s call it example_eval.py
Run the evaluation script from your shell.
For the purpose of this tutorial we are running the evaluation script against the GPT 4o model. However we can select a variety of models to run our evaluation against, to learn more check out the Inspect AI documentation
Note: In order to run the command above you will need to add your OPENAI API Key to the environment variables like so:
View your results
Head over to the evaluations tab on your Langtrace dashboard to view your results.
The target column represents the results from our chatbot while the output column represents the output from the GPT-4o model which we ran our evaluation against.

Conclusion
Our AI chatbot used the OpenAI’s GPT-3.5-turbo, and we ran our evaluation against OpenAI's GPT-4o model. From our evaluation we can see that the GPT 3.5-turbo model is just as accurate as the GPT-4o model and is appropriate for our chatbot.
From a cost standpoint:
GPT 3.5-turbo model: $3 per 1 million input tokens and $6 per 1 million output tokens
GPT 4o model: $5 per 1 million input tokens and $15 per 1 million output tokens
Since GPT 3.5-turbo is just as accurate for our purpose but much cheaper we can go with the GPT 3.5-turbo model and save a ton of money. By running evaluations in Langtrace we were able to make the right decision and save a ton of money!
Of course this is just one use case but in general when working with Large Language Models at scale, evaluations are very useful in ensuring accuracy of our models and choosing a model.
Ready to Get the best out of your LLM Models?
Sign up for Langtrace today and start running comprehensive evaluations to ensure the accuracy and effectiveness of your models. Don’t ship on just vibes. Make data driven decisions and be more confident in your LLM Applications.
Support Our Open Source Project
If you found this tutorial helpful, please consider giving us a star on GitHub . Your support helps us continue to improve as well as share valuable resources with the community. Thank you!
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
