We built a startup within a startup, “by accident”

Jay Thakrar
⸱
Head of Product and Strategy
Jun 20, 2024

Outline
In this blog, I cover:
Why we built Langtrace
Illustrate why LLM application observability and evaluations are imperative tools as part of an LLM tech stack
How product builders of LLM applications can get started with Langtrace
The intended audience for this blog is any individual that is tinkering with and / or leveraging LLMs to build applications.
Why We Built Langtrace
Believe it or not, Langtrace was a tool that we built by “accident”.
Our company, Scale3, consists of builders with collectively over 40 years of observability and reliability experience in web2 and web3. A majority of our team met at Coinbase where they were responsible for managing infrastructure. We left Coinbase and raised money by Redpoint Ventures to build a web3 observability and infrastructure management platform for distributed networks, specifically blockchain networks - Autopilot.
While continuously expanding upon Autopilot’s capabilities, we leveraged AI for two features; (1) NodeGPT - a simple chatbot that helps our users get answers to questions about blockchain node operations; and (2) Intelligent Logs - a logging feature that flags errors and provides recommendations for remediations based on a RAG system we built using the open-source blockchain network codebase. However, there was one problem - we had no visibility into the accuracy of the responses from the chatbot and quickly realized that there is no comprehensive tooling for observability across an LLM stack (e.g. the LLM, vector database, and/or the framework / orchestrator layer).
As observability and reliability enthusiasts, we decided to build an internal tool, Langtrace, to provide observability across our LLM stack. We also developed a feature that collected user feedback as thumbs up / thumbs down down each time the chatbot generated a response. We diligently tracked and measured each output to patch every edge and corner case by fixing our retrieval pipeline. This led us to another problem - how do we make sure our system does not regress with each change (i.e. when a new LLM model version is released, etc.)? We needed to capture a dataset that worked well with our existing system. Luckily, we had a solution for this specific problem, which included extracting the dataset from the observability pipeline. Using a variety of similar techniques, we improved the accuracy of our RAG system from 60% to 90%+ within a couple of months. When we told our developer and founder friends about our story and how we built a scrapply tool internally to solve our problems, we quickly realized that this was a large pain point for them as well, and as a result, we externalized Langtrace in early April. Today, we’re excited to announce that our SDKs have been downloaded over 460K+ times in the last 3 months and over 300+ developers across various companies are using Langtrace for improving their LLM-powered applications. Learn more about why below.
Our Vision
According to McKinsey’s recent report on the state of AI in 2024, 72% of respondents of a recent survey stated that their organizations are leveraging AI and 65% of respondents indicated that they use AI regularly across their organizations. This study reaffirms what we firmly believe - LLMs are a market transformative technology that are here to stay. Furthermore, LLMs will fundamentally change the way product builders develop applications. For example, to integrate an LLM into an application today, developers make API calls (i.e. requests to the inference endpoints of) to an LLM, enabling them to submit inputs (prompts) and capture outputs (responses) from an LLM. However, the APIs of LLMs are black boxes and depending on a variety of factors such as (a) the LLM, (b) the specific model version of the LLM, (c) the input (prompts), and (d) other various factors - the output can change. As a result, software development is evolving from a “deterministic-nature” where code has historically produced binary outcomes to a “nondeterministic-nature” where code may no longer produce binary outcomes.
Given the non-deterministic-outputs of LLM responses, software development will evolve, creating many efficiencies that builders will benefit from coupled with new challenges that product builders will need to overcome. Based on our conversations with many LLM application developers, two of the largest pain points that emerged are:
Trust: How can developers trust an LLM to perform within their application in an accurate, high quality, and reliable manner?
Visibility: How can developers capture key insights into how an LLM is performing within their application and troubleshoot any incidents immediately?
In order to solve these problems, LLM Application Observability and Evaluations are key tools that any developer of an LLM should have in their toolbox. In summary, 2023 was the year of experimentation of Generative AI, however 2024 is the year that enterprises are moving workloads to production, which requires a new set of tooling in order to manage the nondeterministic outputs of LLMs. Our vision is to build a vertically integrated solution to enable enterprises to deploy AI agents at scale in a secure and compliant manner.
The Importance of LLM Application Observability
As large language models (LLMs) like OpenAI’s GPT-4, Google’s Gemini, Meta’s Llama3, and Anthropic’s Claude become more powerful and widely adopted, developers are increasingly building applications on top of these models via Amazon’s Bedrock Studio, Microsoft Azure OpenAI, and Google’s Vertex AI. However, ensuring the reliability, performance, and security of these applications can be challenging due to the complexity and opaqueness of LLMs. This is where observability comes into play.
What is observability?
Observability is the ability to understand the internal state and behavior of a system based on the outputs it produces. It involves collecting, analyzing, and visualizing data from various sources such as logs, metrics, and traces, to gain insights into the system's performance, health, and potential issues.


Why does Observability Matter for LLM Applications?
Observability is paramount for applications built on top of large language models (LLMs) for several reasons:
Monitoring Performance and Reliability: LLM applications often involve complex interactions between the model, user inputs, and other components. Observability tools can help you monitor the performance and reliability of these interactions, enabling you to identify and address bottlenecks, errors, or unexpected behavior.
Ensuring Security and Privacy: LLMs can inadvertently expose sensitive information, or generate harmful or biased content. Observability can help you detect and mitigate such risks by monitoring the inputs and outputs, allowing you to take appropriate actions when necessary.
Improving User Experience: By monitoring user interactions and model outputs, observability can provide valuable insights into user behavior and preferences. This information can be used to optimize the user experience, personalize content, and improve the overall quality of the application.
Facilitating Debugging and Troubleshooting: When issues arise in LLM applications, observability tools can help you quickly identify the root cause by providing detailed logs, traces, and metrics. This can significantly reduce the time and effort required for debugging and troubleshooting.
Enabling Continuous Improvement: Observability data can be used to continuously improve the performance, reliability, and security of LLM applications. By analyzing historical data and identifying patterns or trends, you can make informed decisions about optimizations, updates, or architectural changes.
To achieve observability in LLM applications, you can leverage various tools and practices, such as:
Logging: Implement comprehensive logging mechanisms to capture relevant information about user inputs, model outputs, and application events.
Metrics: Define and collect key performance indicators (KPIs) and other metrics related to model performance, response times, error rates, and resource utilization.
Tracing: Use distributed tracing to understand the flow of requests and interactions between different components of your application.
Monitoring and Alerting: Set up monitoring and alerting systems to proactively detect and respond to issues or anomalies in your LLM application.
Observability Platforms: Leverage Langtrace’s SDKs (which are open-source and built using OpenTelemetry standards that can easily be integrated into your existing observability visualization platform such as Grafana, Signoz, Datadog, New Relic, Honeycomb, Cribl, and others) or leverage Langtrace’s platform for end-to-end observability of your LLM application.
By embracing observability practices and tools, you can build more reliable, secure, and user-friendly LLM applications, while also enabling continuous improvement and maintaining a competitive edge in the rapidly evolving field of AI.
The Importance of LLM Application Evaluations
LLM Application Evaluations is a process of assessing the performance, quality, and effectiveness of LLM-powered systems. The purpose of conducting evaluations of how an LLM performs within your application is for product builders to measure the accuracy of an LLM’s response, and confirm if an LLM is producing cohesive responses with the appropriate context, tonality, and conciseness; thereby building trust amongst the LLM application developer community.
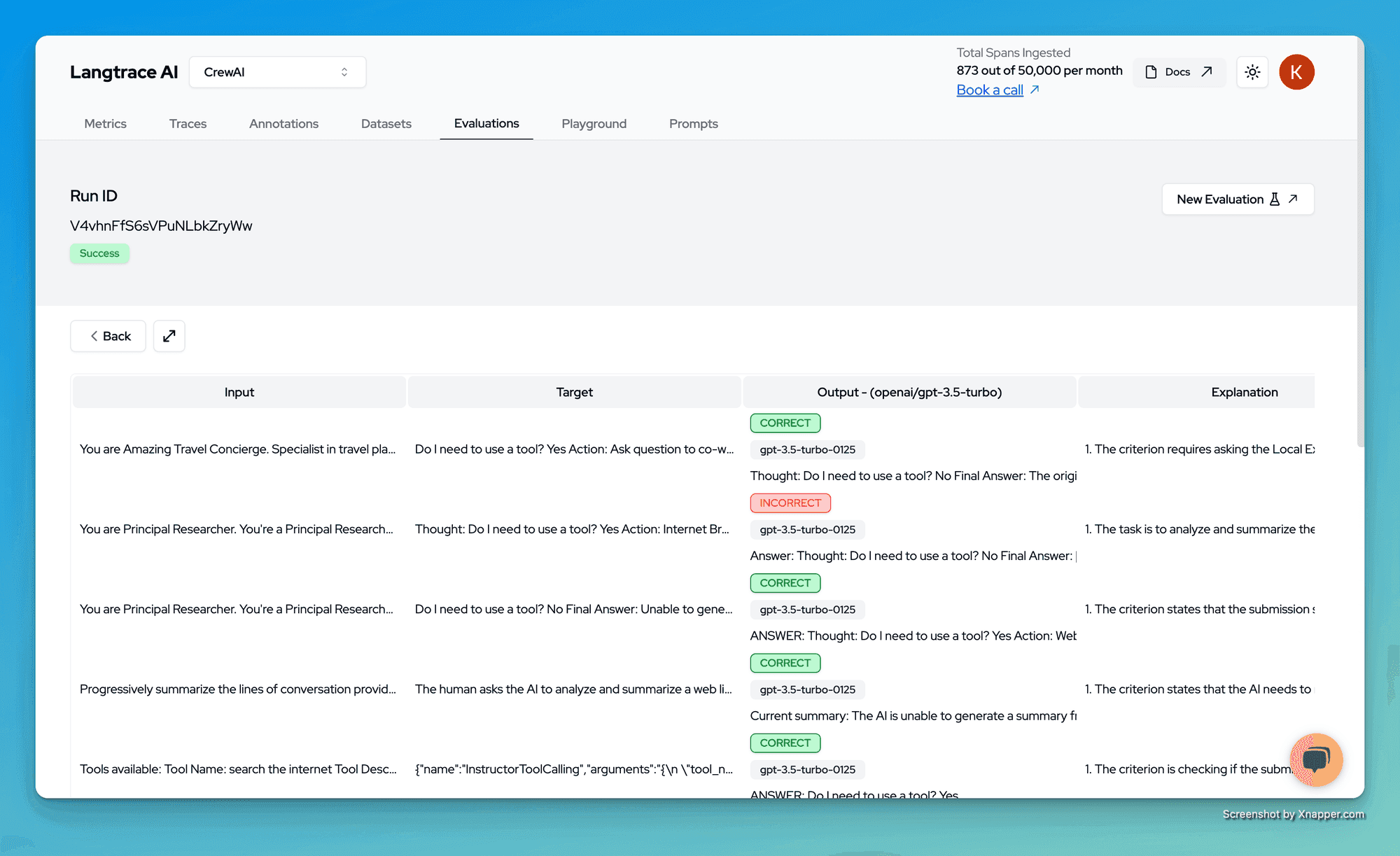
Why does Evaluations Matter for LLM Applications?
Evaluations are crucial for applications built on top of large language models (LLMs) for several reasons:
Ensuring output quality and accuracy: LLMs can sometimes generate outputs that are inaccurate, irrelevant, or biased. Evaluations help identify these issues, ensuring the application provides high-quality and reliable information to users. Without evaluations, applications risk delivering incorrect or harmful content, damaging user trust and the business's reputation.
Aligning with intended use and user expectations: Different applications have varying requirements for tone, style, and content appropriateness. Evaluations allow developers to assess whether the LLM's outputs align with the intended use case and meet user expectations. For example, a customer support chatbot may require a friendly, helpful tone, while a content generation tool needs factual, unbiased information.
Identifying biases and ethical concerns: LLMs can inadvertently perpetuate societal biases or generate outputs that raise ethical concerns. Evaluations help detect and address these issues, ensuring the application operates ethically and avoids causing harm. Failing to evaluate for biases could lead to discrimination or the spread of misinformation.
Enabling continuous improvement: Evaluations provide valuable feedback that can be used to fine-tune the LLM or adjust the prompts and input data, improving the application's performance over time. Without evaluations, it becomes challenging to identify areas for improvement or measure the impact of changes made to the system.
Ensuring regulatory compliance: In certain industries or regions, there may be regulations or guidelines around the use of AI systems, including requirements for testing and evaluation. Evaluations help demonstrate compliance and mitigate legal risks associated with deploying LLM-based applications.
Facilitating collaboration and alignment: Evaluations create a shared understanding of the application's strengths, weaknesses, and areas for improvement among stakeholders, including developers, subject matter experts, and end-users. This alignment is crucial for effective collaboration and decision-making.
What does Evaluations for for LLM Applications look like?
When conducting evaluations of how an LLM performs within your application, it’s important to take a holistic approach, including:
How your system is performing end-to-end.
How individual layers within your system, e.g. the LLM layer, the database layer, and/or the orchestrator / framework layer are performing, in the event an incident or error occurs.
Establish a continuous feedback loop of tracing, annotating, evaluating, tweaking and improving your system over time.
However, evaluating the responses of LLMs is an ambiguous and open-ended problem today. LLM evaluations are experimental processes that require constant iteration and collaboration. The general workflows for conducting evaluations of how an LLM performs within your application largely overlaps with the best practices associated with LLM application observability, which is why it is imperative that developers of LLM applications leverage a comprehensive tool such as Langtrace as part of their LLM application tech stack.
The LLM application evaluations workflow includes:

Develop
Create, test, iterate, and version your prompts against various LLMs in terms of overall performance and costs
Trace
Collect and analyze the traces and logs from your application
Evaluate
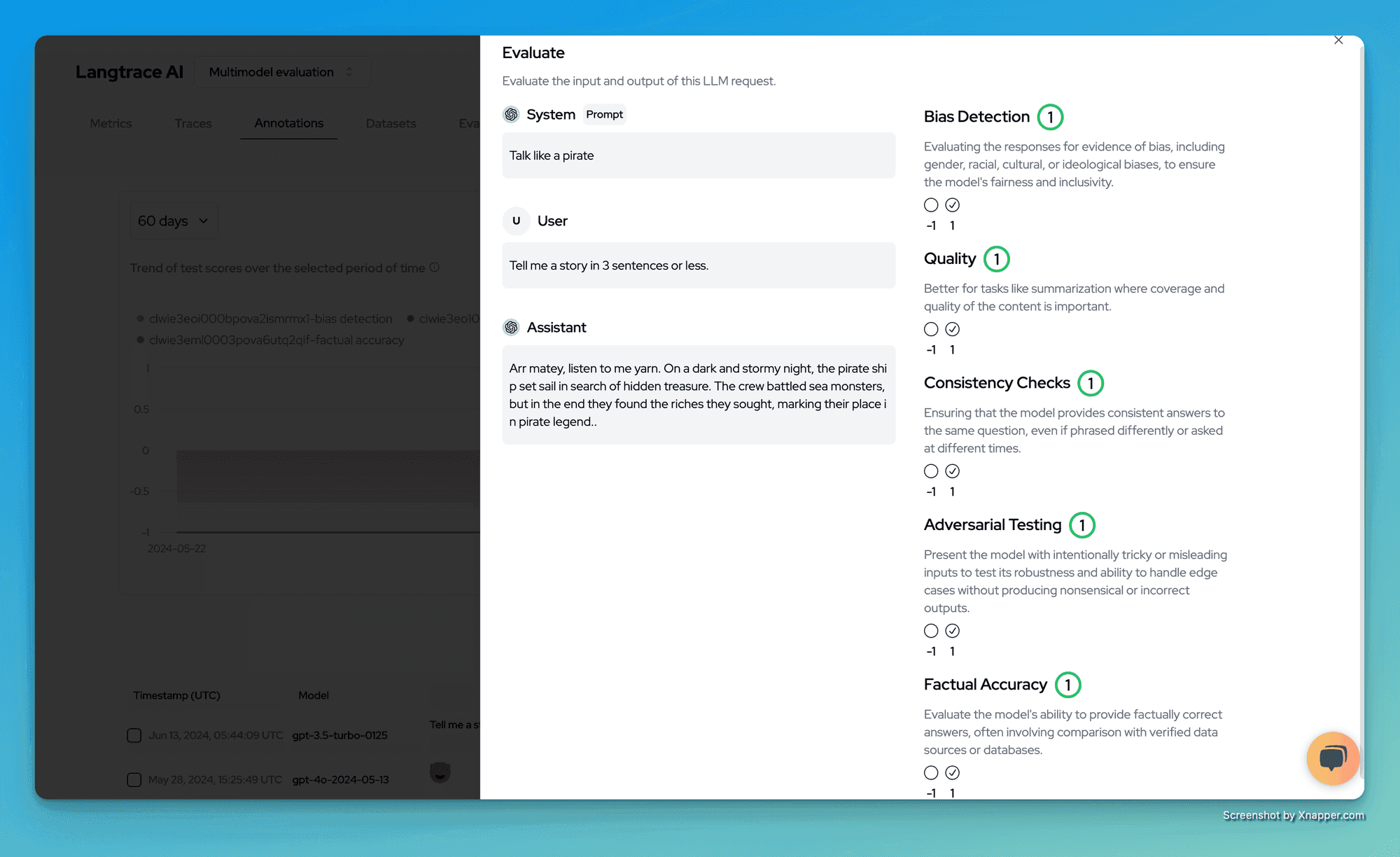
Use "Human in the Loop" (HITL), which refers to the process where human evaluators are actively involved in assessing and improving the performance of LLMs, to manually annotate and curate the data from captured traces to measure the accuracy and create a golden dataset for further testing and evaluations.
Collect user feedback using a thumbs up / down methodology, and systematically use the collected data points to fix any corner and edge cases.
Run automated, model based evaluations (LLM as a judge) against the curated datasets to test for regressions each time you tweak and release a new version of your system
Note that there are multiple ways to conduct evaluations, and not all evaluations are equal, meaning each methodology has trade-offs that every developer must consider. For example, today, most evaluations are conducted using human evaluations. Despite this methodology being the most trusted in ensuring an LLM performs optimally within your application, it is extremely time-consuming and expensive. As a result, a new methodology that’s becoming increasingly popular are automatic evaluations, whereby an oracle LLM serves as a “judge” and compares and conducts evaluations of responses from various other LLMs. For more information on best practices of conducting evaluations of LLM powered applications, check out our previous blog on How to Evaluate LLM Powered Applications.
Neglecting evaluations can lead to inaccurate or harmful outputs, user dissatisfaction, and potential legal or reputational risks. In summary, conducting evaluations of how an LLM performs within your applications is table stakes during pre-production and post-production of your application.
How to Get Started with Langtrace
Langtrace is an open-source and OpenTelemetry-based observability and evaluations SDK and platform designed to improve your LLM applications. Developers can use Langtrace to iterate on prompts, set up automatic tracing and logging of their LLM stack, curate datasets and conduct evaluations. The onboarding process is simple and non-intrusive, it only takes two lines of code to get started. Visit the Langtrace website to get started today.
Summary of Resources:
Visit the Langtrace Website
Visit the Langtrace Docs
Visit the Langtrace Blog
Join the Langtrance Community Discord
Contribute via the GitHub Repository
Join the LLM Semantics Working Group (run by CNCF and OpenTelemetry)
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
