Supercharging AI Workloads: Observability with Langtrace x Cerebras

Ali Waleed
⸱
Software Engineer
Nov 19, 2024

Introduction
As artificial intelligence scales to new heights, the demand for faster and more efficient inference grows exponentially. Cerebras, a leader in AI hardware and cloud solutions, enables unprecedented performance for large language models, pushing the boundaries of what’s possible in AI.
However, optimizing such powerful systems requires deep insights into how models are executed, resources are utilized, and where potential bottlenecks lie. This is where Langtrace comes in. By integrating Langtrace with Cerebras, developers gain real-time observability into their AI workloads, providing actionable insights to monitor, debug, and optimize performance.
In this guide, we’ll explore how Langtrace x Cerebras works in action. We’ll demonstrate examples using Cerebras’s Llama-based models and OpenAI endpoints, showcasing how Langtrace traces each operation, tracks key metrics, and helps you unleash the full potential of your AI pipelines. Let’s dive in!
Why Observability in AI Inference Is Essential
In the race to deploy cutting-edge AI models, inference speed and efficiency are critical. Platforms like Cerebras enable unparalleled performance for large-scale models, but with this power comes complexity. As models grow larger and workloads become more distributed, monitoring and optimizing their behavior is no longer a luxury—it’s a necessity.
Here’s why observability in AI inference matters:
• Identify Bottlenecks: Gain insights into latency, throughput, and resource utilization to pinpoint inefficiencies in your pipeline.
• Optimize Resource Usage: Ensure your hardware resources (e.g., GPUs, TPUs) are being used effectively without overloading.
• Debug Complex Pipelines: Trace errors or anomalies in distributed workloads, streamlining troubleshooting for both synchronous and asynchronous operations.
• Improve User Experience: Faster, more reliable inference translates to better outcomes for end-users.
By integrating Langtrace with Cerebras, you bring observability to every stage of the pipeline. From handling streaming responses to batch completions, Langtrace provides the transparency needed to fine-tune performance and ensure seamless operations. Let’s move on to a step-by-step walkthrough of how this integration works.
Step-by-Step Walkthrough: Langtrace x Cerebras in Action
Let’s dive into the code to see how Langtrace integrates with Cerebras, enhancing observability at each step of the pipeline. Below, we’ll break down key functions and highlight what insights you can capture with Langtrace.
Cerebras Completion Example
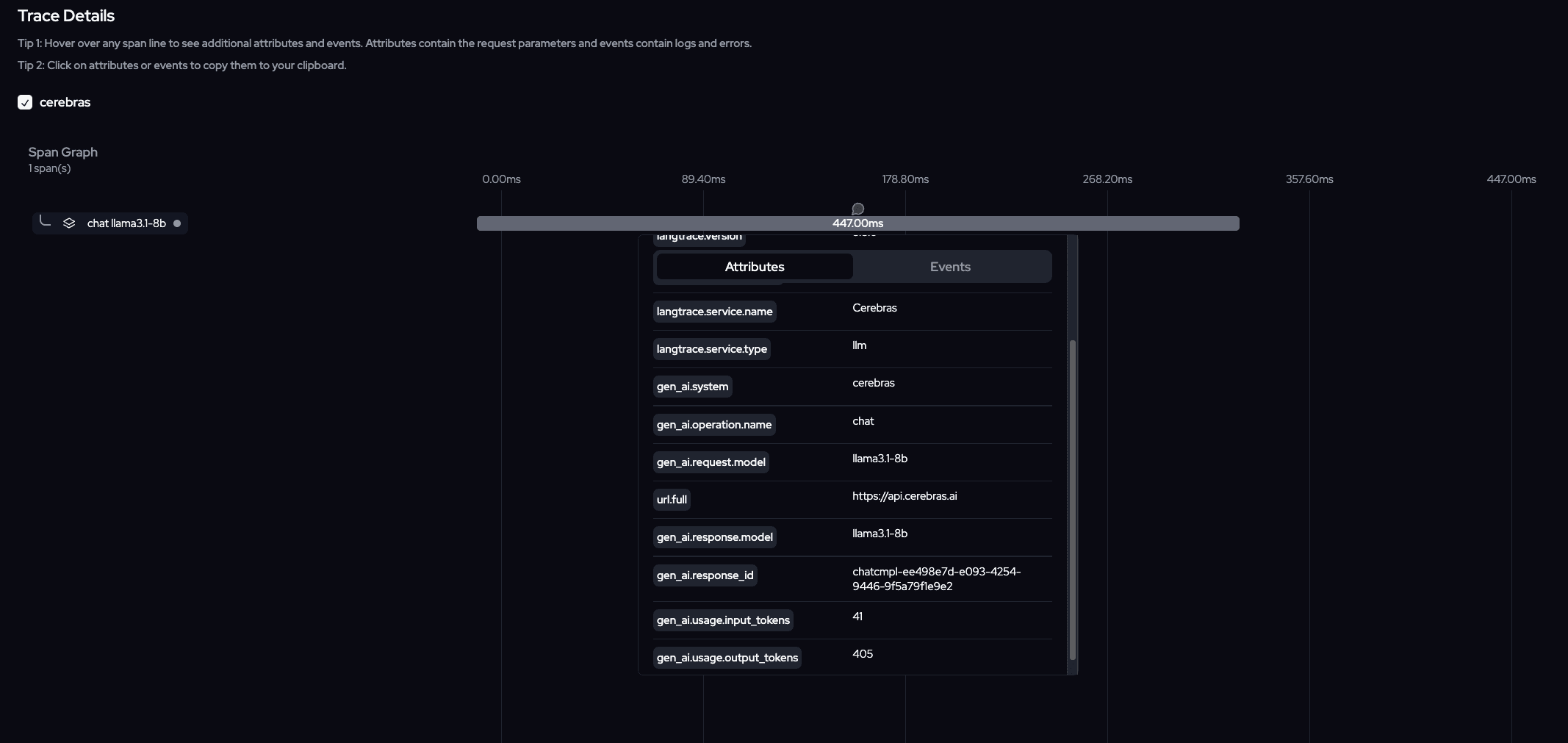
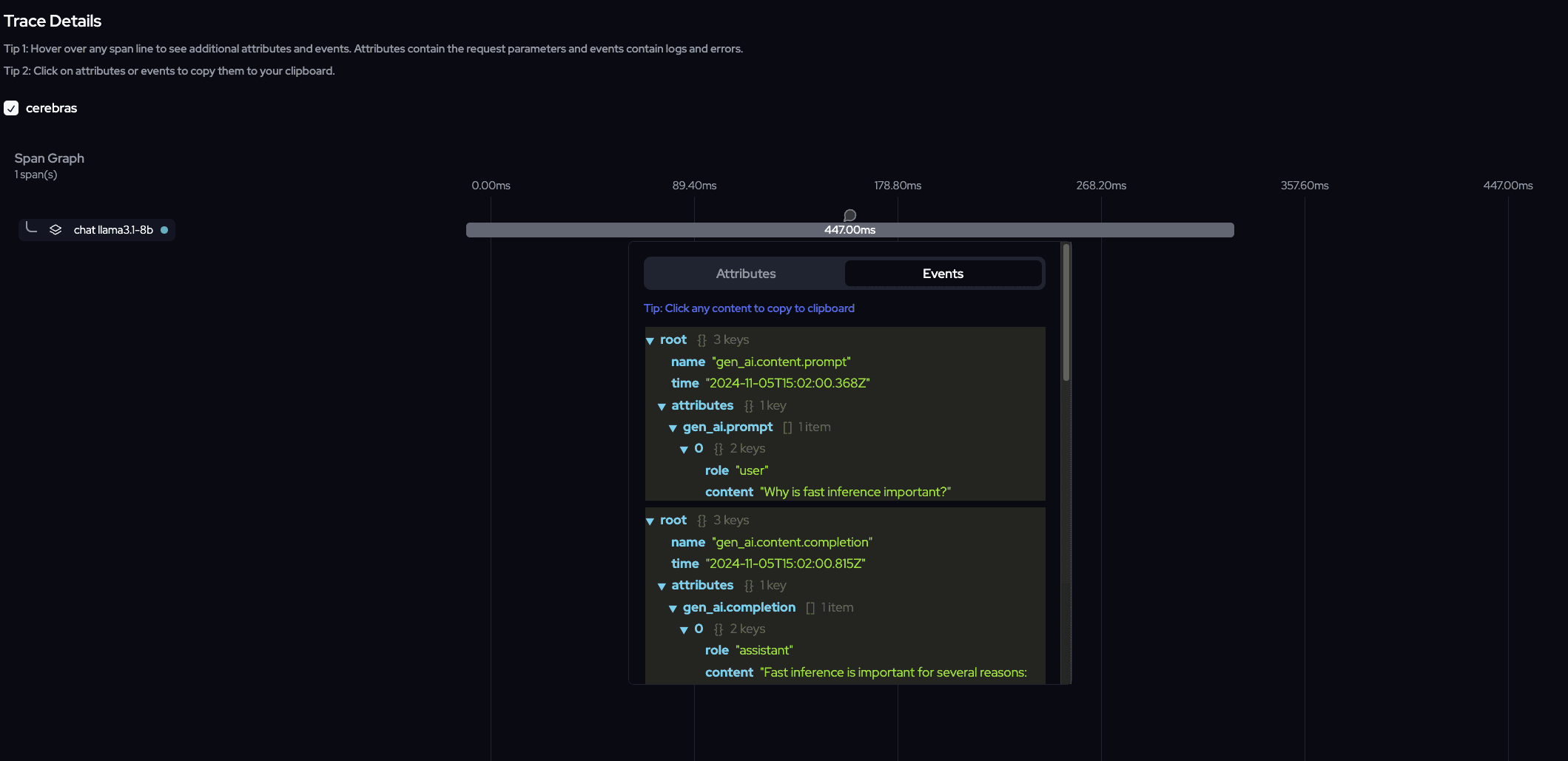
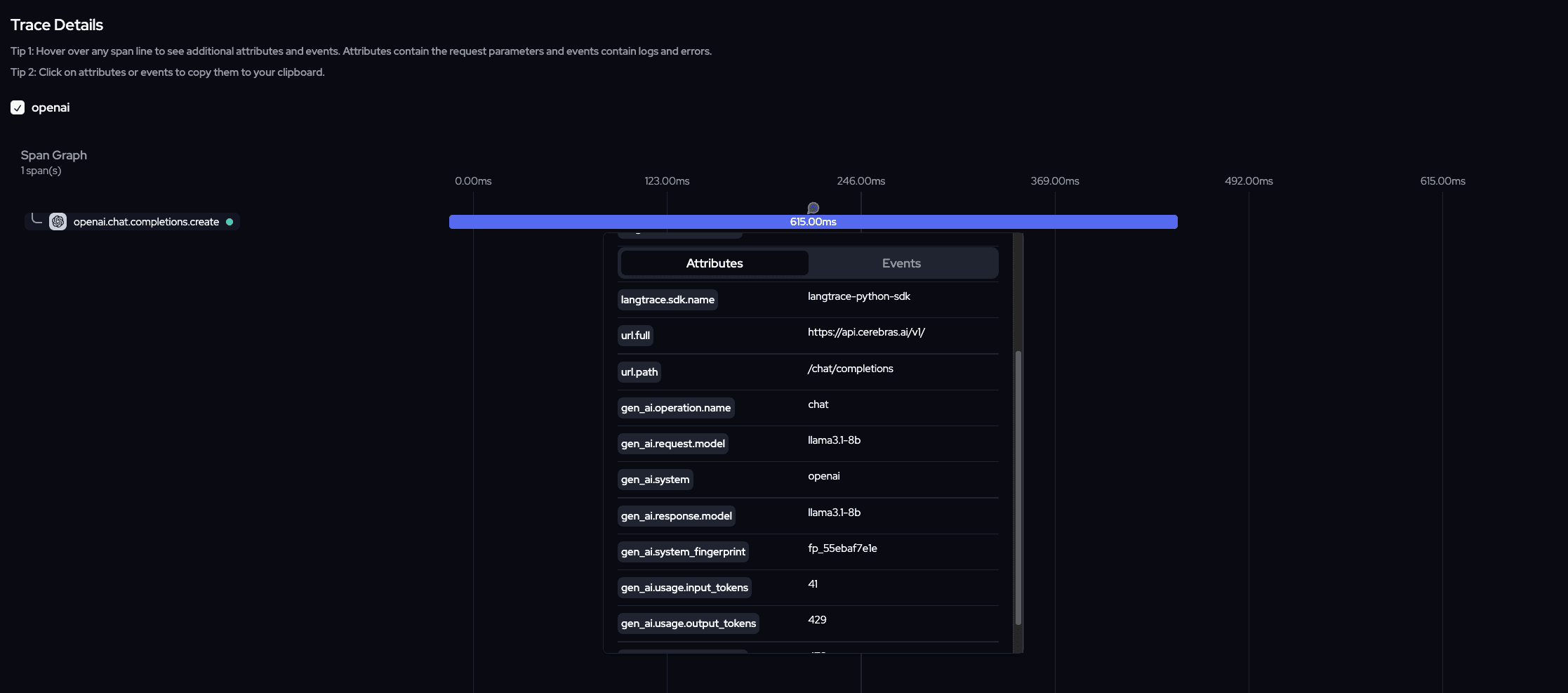
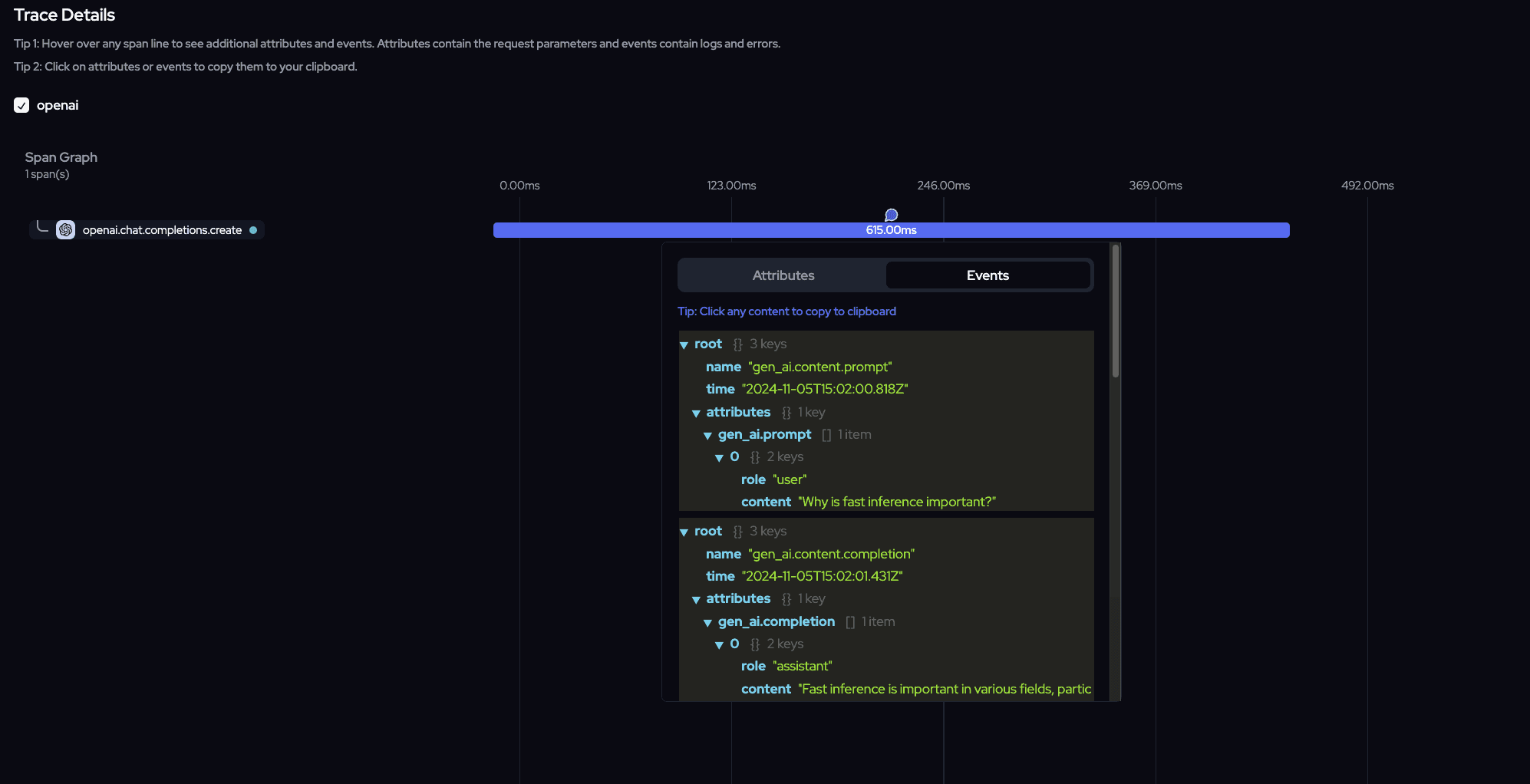
Cerebras Completion Example Using OpenAI
Conclusion
The integration of Langtrace with Cerebras brings observability to cutting-edge AI infrastructure, offering developers unparalleled insights into their AI workloads. By tracing operations like model execution, streaming responses, and resource utilization, Langtrace empowers you to optimize performance, debug complex pipelines, and ensure seamless user experiences.
Cerebras’s innovative hardware and cloud solutions unlock the potential of large-scale AI models, and Langtrace complements this by providing the transparency needed to manage and fine-tune every step of your workflow. From setting up OpenAI endpoints on Cerebras to running complex inference tasks, Langtrace ensures that no detail goes unnoticed.
Ready to take your AI observability to the next level? Try Langtrace x Cerebras today and bring precision, performance, and peace of mind to your AI deployments. 🚀
Useful Resources
Getting started with Langtrace https://docs.langtrace.ai/introduction
Langtrace Github https://github.com/Scale3-Labs/langtrace
Langtrace Website https://langtrace.ai/
Langtrace Discord https://discord.langtrace.ai/
Langtrace Twitter(X) https://x.com/langtrace_ai
Langtrace Linkedin https://www.linkedin.com/company/langtrace/about/
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
