Introduction
In this blog post, we'll walk through the process of sending traces from Langtrace, an OpenTelemetry open-source LLM monitoring tool, to New Relic using OpenTelemetry (OTEL). This integration allows you to leverage New Relic's powerful observability platform for monitoring your LLM applications.
Prerequisites
A New Relic account with an API key
Python 3.x installed
OpenAI API Key
Step 1: Set Up Your Environment
First, let's set up our environment variables and create a virtual environment:
# Set environment variables
export OTEL_SERVICE_NAME=qdrant-demo
export OTEL_EXPORTER_OTLP_ENDPOINT=https:
export OTEL_EXPORTER_OTLP_HEADERS=api-key=YOUR_NEW_RELIC_API_KEY
export OPENAI_API_KEY=your_openai_api_key_here
# Create and activate virtual environment
python3 -m venv venv
source ./venv/bin/activate
# Upgrade pip
pip install --upgrade pip
Replace YOUR_NEW_RELIC_API_KEY with your actual New Relic API key.
Step 2: Install Required Packages
Create a requirements.txt file with the following contents:
opentelemetry-api==1.24.0
opentelemetry-sdk==1.24.0
opentelemetry-exporter-otlp-proto-http==1.24.0
opentelemetry-instrumentation==0.45b0
opentelemetry-distro==0.45b0
langtrace-python-sdk
openai
qdrant-client
fastembed==0.3.4
Then install the packages:
pip install -Uq -r requirements.txt
Step 3: Install and Configure OpenTelemetry
Install the OpenTelemetry SDK:
opentelemetry-bootstrap -a install
Step 4: Integrate Langtrace with Your Application
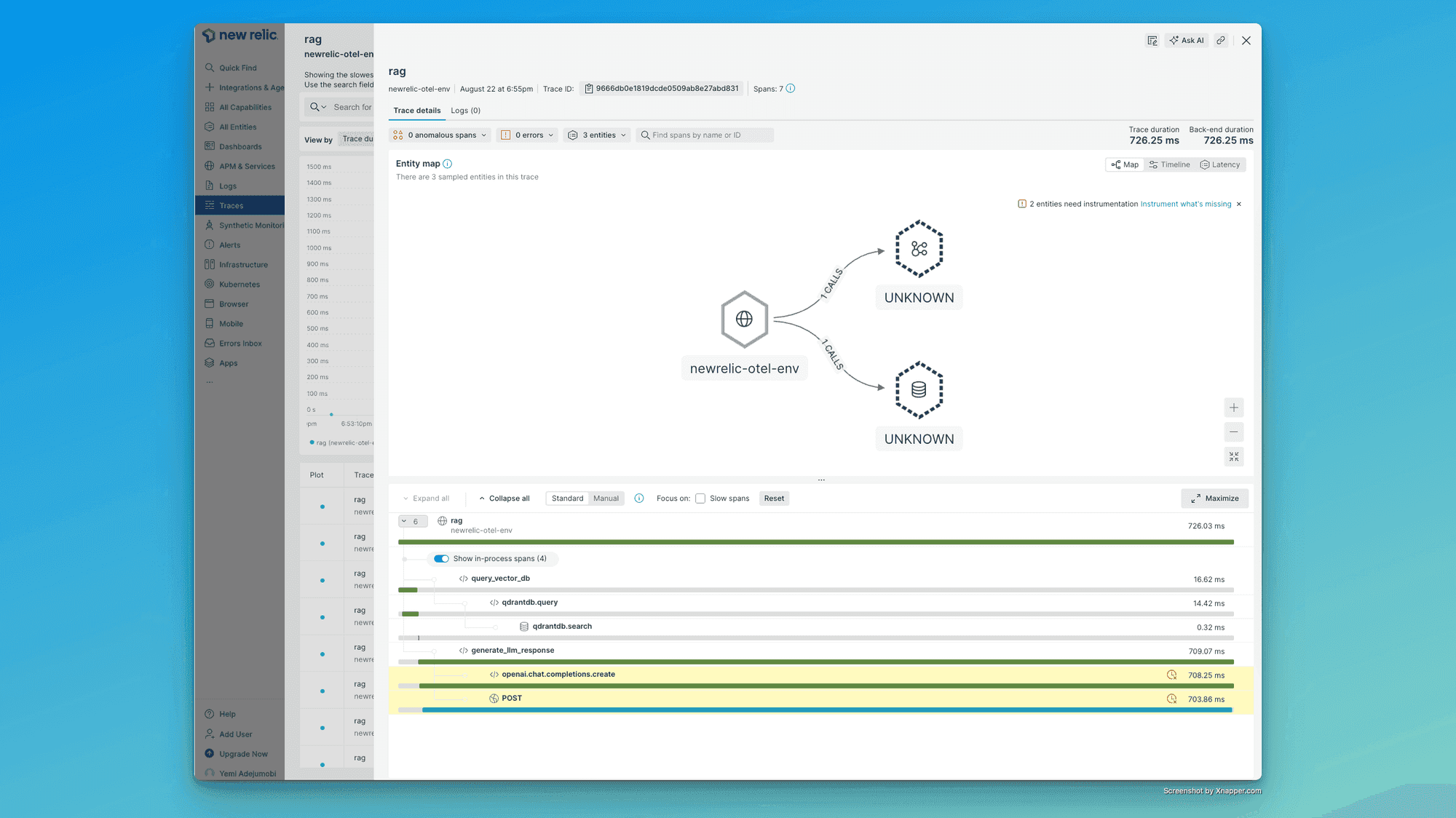
Here's a complete Python script that demonstrates how to use Langtrace with OpenAI and Qdrant. This script demonstrates a basic implementation of a Retrieval-Augmented Generation (RAG) system using Langtrace for monitoring, Qdrant as a vector database, and OpenAI for language model responses.
Create a file named newrelic-langtrace.py with the following content:
import os
import openai
from qdrant_client import QdrantClient
from langtrace_python_sdk import langtrace, with_langtrace_root_span
from typing import List, Dict, Any
from dotenv import load_dotenv
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
# Load environment variables from .env file
load_dotenv()
# OpenTelemetry settings
OTEL_EXPORTER_OTLP_ENDPOINT = os.getenv("OTEL_EXPORTER_OTLP_ENDPOINT")
OTEL_SERVICE_NAME = os.getenv("OTEL_SERVICE_NAME")
OTEL_EXPORTER_OTLP_HEADERS = os.getenv("OTEL_EXPORTER_OTLP_HEADERS")
# Parse headers
headers = {}
if OTEL_EXPORTER_OTLP_HEADERS:
key_value = OTEL_EXPORTER_OTLP_HEADERS.split('=', 1)
if len(key_value) == 2:
headers[key_value[0]] = key_value[1]
# Add Content-Type header
headers["Content-Type"] = "application/json"
# Configure the OTLP exporter
otlp_exporter = OTLPSpanExporter(
endpoint=f"{OTEL_EXPORTER_OTLP_ENDPOINT}:443/v1/traces",
headers=headers
)
# Initialize Langtrace with New Relic exporter
langtrace.init(
custom_remote_exporter=otlp_exporter,
batch=True,
)
# Initialize environment and clients
openai_api_key = os.getenv("OPENAI_API_KEY")
if not openai_api_key:
raise ValueError("OPENAI_API_KEY not found in .env file")
openai_client = openai.Client(api_key=openai_api_key)
qdrant_client = QdrantClient(":memory:")
@with_langtrace_root_span("initialize_knowledge_base")
def initialize_knowledge_base(documents: List[str]) -> None:
try:
qdrant_client.add(
collection_name="knowledge-base",
documents=documents
)
print(f"Knowledge base initialized with {len(documents)} documents")
except Exception as e:
print(f"Error initializing knowledge base: {str(e)}")
@with_langtrace_root_span("query_vector_db")
def query_vector_db(question: str, n_points: int = 3) -> List[Dict[str, Any]]:
results = qdrant_client.query(
collection_name="knowledge-base",
query_text=question,
limit=n_points,
)
print(f"Vector DB queried, returned {len(results)} results")
return results
@with_langtrace_root_span("generate_llm_response")
def generate_llm_response(prompt: str, model: str = "gpt-3.5-turbo") -> str:
completion = openai_client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt},
],
timeout=10.0,
)
response = completion.choices[0].message.content
print(f"LLM response generated")
return response
@with_langtrace_root_span("rag")
def rag(question: str, n_points: int = 3) -> str:
print(f"Processing RAG for question: {question}")
context = "\\n".join([r.document for r in query_vector_db(question, n_points)])
metaprompt = f"""
You are a software architect.
Answer the following question using the provided context.
If you can't find the answer, do not pretend you know it, but answer "I don't know".
Question: {question.strip()}
Context:
{context.strip()}
Answer:
"""
answer = generate_llm_response(metaprompt)
print(f"RAG completed, answer length: {len(answer)} characters")
return answer
# @with_langtrace_root_span("demonstrate_different_queries")
def demonstrate_different_queries():
questions = [
"What is Qdrant used for?",
"How does Docker help developers?",
"What is the purpose of MySQL?",
"Can you explain what FastAPI is?",
]
for question in questions:
try:
answer = rag(question)
print(f"Question: {question}")
print(f"Answer: {answer}\\n")
except Exception as e:
print(f"Error processing question '{question}': {str(e)}\\n")
if __name__ == "__main__":
# Initialize knowledge base
documents = [
"Qdrant is a vector database & vector similarity search engine. It deploys as an API service providing search for the nearest high-dimensional vectors. With Qdrant, embeddings or neural network encoders can be turned into full-fledged applications for matching, searching, recommending, and much more!",
"Docker helps developers build, share, and run applications anywhere — without tedious environment configuration or management.",
"PyTorch is a machine learning framework based on the Torch library, used for applications such as computer vision and natural language processing.",
"MySQL is an open-source relational database management system (RDBMS). A relational database organizes data into one or more data tables in which data may be related to each other; these relations help structure the data. SQL is a language that programmers use to create, modify and extract data from the relational database, as well as control user access to the database.",
"NGINX is a free, open-source, high-performance HTTP server and reverse proxy, as well as an IMAP/POP3 proxy server. NGINX is known for its high performance, stability, rich feature set, simple configuration, and low resource consumption.",
"FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.7+ based on standard Python type hints.",
"SentenceTransformers is a Python framework for state-of-the-art sentence, text and image embeddings. You can use this framework to compute sentence / text embeddings for more than 100 languages. These embeddings can then be compared e.g. with cosine-similarity to find sentences with a similar meaning. This can be useful for semantic textual similar, semantic search, or paraphrase mining.",
"The cron command-line utility is a job scheduler on Unix-like operating systems. Users who set up and maintain software environments use cron to schedule jobs (commands or shell scripts), also known as cron jobs, to run periodically at fixed times, dates, or intervals.",
]
initialize_knowledge_base(documents)
demonstrate_different_queries()
Step 5: Run the application
opentelemetry-instrument python newrelic-langtrace.py
Alternative: Using the run.sh Script
For those who prefer an automated setup, we've provided a run.sh script in our GitHub repository that handles the entire process for you. This script automates the environment setup, package installation, and application execution. To use it:
git clone <https://github.com/Scale3-Labs/langtrace-recipes.git>
Navigate to the correct directory:
cd integrations/observability/new-relic/qdrant-rag
Make the script executable:
chmod +x run.sh
./run.sh
This script will set up your environment, install all necessary packages, and run the application with OpenTelemetry instrumentation, making it easier to get started with the Langtrace to New Relic integration.
Understanding the Script
Let's break down the key components of the provided script:
1. Imports and Initialization
import os
import time
import openai
from qdrant_client import QdrantClient
from langtrace_python_sdk import langtrace, with_langtrace_root_span
from typing import List, Dict, Any
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
langtrace.init(api_key='YOUR_LANGTRACE_API_KEY')
qdrant_client = QdrantClient(":memory:")
openai_client = openai.Client(api_key=os.getenv("OPENAI_API_KEY"))
This section imports necessary libraries and initializes the Langtrace, Qdrant, and OpenAI clients. Note that you should replace the dummy API keys with your actual keys.
2. Knowledge Base Initialization
@with_langtrace_root_span("initialize_knowledge_base")
def initialize_knowledge_base(documents: List[str]) -> None:
This function initializes the knowledge base with provided documents. The @with_langtrace_root_span decorator creates a trace for this operation.
3. Vector Database Querying
@with_langtrace_root_span("query_vector_db")
def query_vector_db(question: str, n_points: int = 3) -> List[Dict[str, Any]]:
This function queries the vector database to find relevant documents based on the input question.
4. LLM Response Generation
@with_langtrace_root_span("generate_llm_response")
def generate_llm_response(prompt: str, model: str = "gpt-3.5-turbo") -> str:
This function generates a response using the OpenAI API based on the given prompt.
5. RAG (Retrieval-Augmented Generation) Implementation
@with_langtrace_root_span("rag")
def rag(question: str, n_points: int = 3) -> str:
This function implements the RAG process, combining vector database querying and LLM response generation.
6. Demonstration and Main Execution
def demonstrate_different_queries():
if __name__ == "__main__":
This section demonstrates the usage of the RAG function with different queries and initializes the knowledge base.
Running the Script
To run this script:
Save it as new_relic_langtrace.py (or any preferred name).
Ensure you have all required libraries installed (openai, qdrant_client, langtrace_python_sdk).
Replace the dummy API keys with your actual keys.
Run the script using:
opentelemetry-instrument python new_relic_langtrace.py
This will execute the script with OpenTelemetry instrumentation, sending traces to New Relic.
Conclusion
By following these steps, you've successfully set up your environment to send traces from Langtrace to New Relic using OpenTelemetry. This integration allows you to monitor your LLM applications more effectively, leveraging New Relic's powerful observability platform.
To make the setup process even easier, we've provided a complete end-to-end script in a GitHub repository. You can clone this repository and run the run.sh file to automatically install all the required libraries and set up the environment. Here's how you can do it:
git clone <https:
cd integrations/observability/new-relic/qdrant-rag
chmod +x run.sh
./run.sh
This script will handle all the necessary installations and configurations, making it simple to get started with sending traces from Langtrace to New Relic.
By leveraging this setup, you'll be able to gain valuable insights into your LLM applications' performance and behavior through New Relic's comprehensive observability platform.
For a more comprehensive understanding of Langtrace and its capabilities, we highly recommend exploring our official documentation. Our docs provide in-depth information on installation, configuration, advanced usage, and best practices for integrating Langtrace with various LLM applications.
Visit our documentation at: https://docs.langtrace.ai
Langtrace <> New Relic Integration documentation can be found here.
Happy monitoring!