Implementing RAG using LlamaIndex, Pinecone and Langtrace: A Step-by-Step Guide

Obinna Okafor
⸱
Software Engineer
Aug 12, 2024

Introduction
In today's data-driven world, the need for quicker and more efficient ways to process and utilize information has never been more crucial. Most LLMs are trained on a vast range of public data up to a specific point in time so when a model is queried about information not publicly available or beyond it's cutoff date (i.e. data not used in training it), it will most likely hallucinate i.e. make something up or respond with out-of-date information. Sometimes these hallucinations can appear quite convincing so some extra effort might be required to prevent them (this is where monitoring and evaluations play a big role but more on that later in this post).
For LLMs to give relevant and specific responses outside of their training data, additional context is required by the model. This is where RAG (Retrieval Augmented Generation) come in. This blog post aims to walk you through the steps involved in implementing an effective RAG system using tools like Llama-Index, Pinecone, and Langtrace.
As the name indicates, there are 3 main steps involved in building RAG:
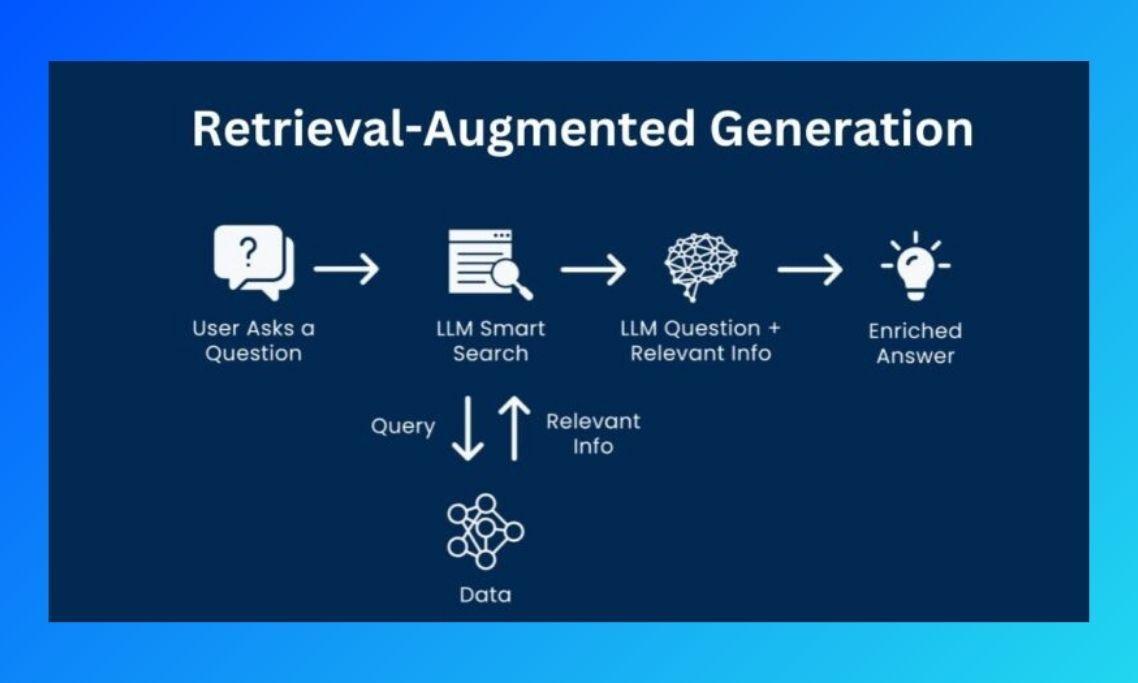
Retrieval - This process involves identifying and fetching relevant data from a large dataset by narrowing it down the large dataset to focus only on the most relevant pieces of information. This helps stay under the LLM token limit (the number of input tokens an LLM can accept).
Augmentation - The data obtained from the "Retrieval" step can either be added as a system prompt, prepended to the query or using some other technique in order to make the data available to the LLM to provide the necessary context relevant to the query.
Generation - Using the augmented data, generate a coherent and context-aware output. This is done using language models that can understand and use the context provided to produce useful responses.
To demonstrate this, we'll be using:
LlamaIndex: We'll be using LlamaIndex to import and index data from a local file. Additionally, LlamaIndex can also import data from other sources such as databases, API endpoints etc. The data will then be converted to embeddings - numerical representations of words or phrases that capture their meanings in a way that can be processed by the model. This might be an oversimplification, but I like to think of the relationship of embeddings to LLMs being similar to the way operating systems work with bits of data.
Pinecone: After the data has been transformed to embeddings, the embeddings will be stored in a vector database from where it can be queried. We'll be using Pinecone as our vector database of choice to store these vector embeddings generated from our data.
The dataset used for this demonstration is a list of ~17k food items from multiple restaurants in Lagos, Nigeria stored in JSON.
First step is installing and importing LlamaIndex and Pinecone
Note: you'll need API keys from OpenAI and Pinecone
Set up environment variables
Create a Pinecone index
When creating a Pinecone index, you'll need to specify a unique name for the index which can be used to query embeddings stored under that index. The index has a dimension of 1536 and uses cosine similarity, which is the recommended metric for comparing vectors produced by the OpenAI's text-embedding-ada-002
model we'll be using to create the embeddings before they are stored in Pinecone.
LlamaIndex supports over 20 different vector store options, including Pinecone which we'll be using to interact with our Pinecone instance via the previously created index. This object will serve as the storage and retrieval interface for our document embeddings in Pinecone's vector database.
Next, we'll load the data from a directory named datastore using the SimpleDirectoryReader module from LlamaIndex. Then create the VectorStoreIndex handles the indexing and querying process, making use of the provided storage and service contexts.
Finally we can build a query engine from the index we build and use this engine to perform a query.
This is what the code looks like put together
How it works
Before we run the script, let's take a look at what exactly is supposed to happen.
LlamaIndex creates the embeddings using OpenAI's embedding API, connects to your Pinecone instance using the index name, stores those embeddings in Pinecone, pulls the relevant context, according to the query, from the vector embedding store and finally sends the query (with the context) to the LLM (in this case, OpenAI).
This is a lot that happens behind the scenes and we might want to see how all this plays out i.e. a breakdown of the processes. To do that, we need a tool that captures these events and shows us what each of them entail and this is where Langtrace comes in (earlier, I mentioned monitoring playing a big role in debugging).
Langtrace is an LLM observability platform that enables you monitor and evaluate the performance of LLM applications. it works seamlessly with most LLMs, LLM frameworks, vector databases.
Adding Langtrace to a project is straightforward as it only requires as little as 2 lines of code to get it running. First we create an account on Langtrace, create a project, then create an API key for the project.
Add Langtrace to your code (second and last lines below)
Finally, we run the code to see what response we get
python3 main.py
The response is as follows:
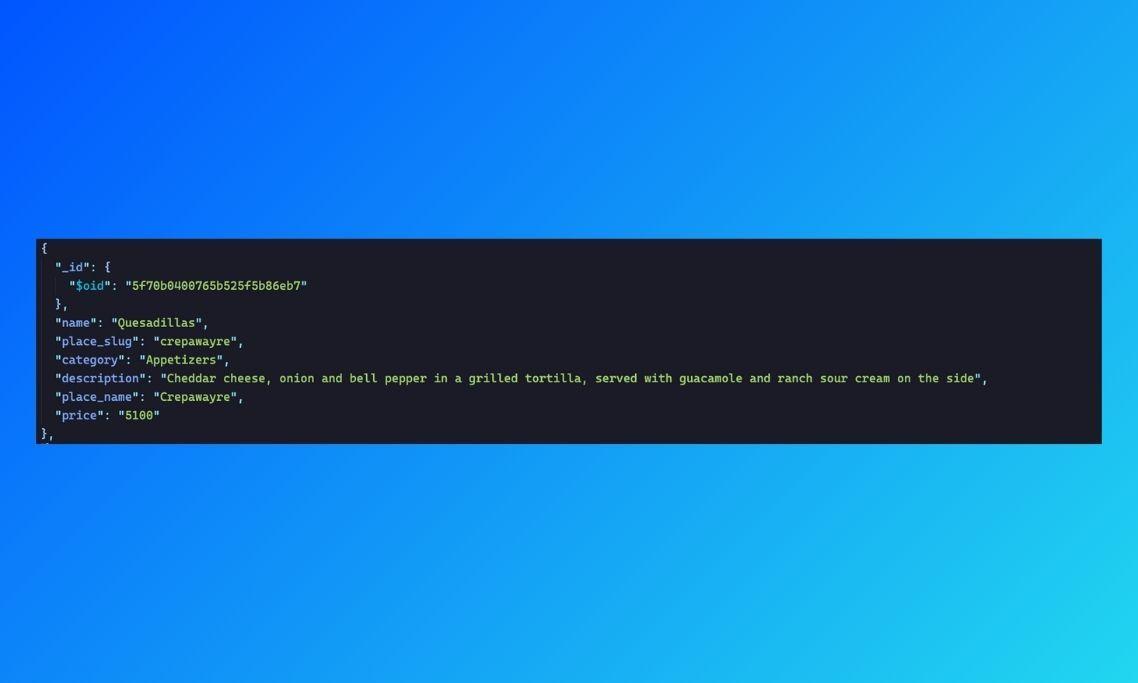
The price of the Quesadillas at Crepawayre is 5100.
Looking at the data we can see that the response was accurate
Now let's take a look at our Langtrace dashboard to see all that took place as the code ran.
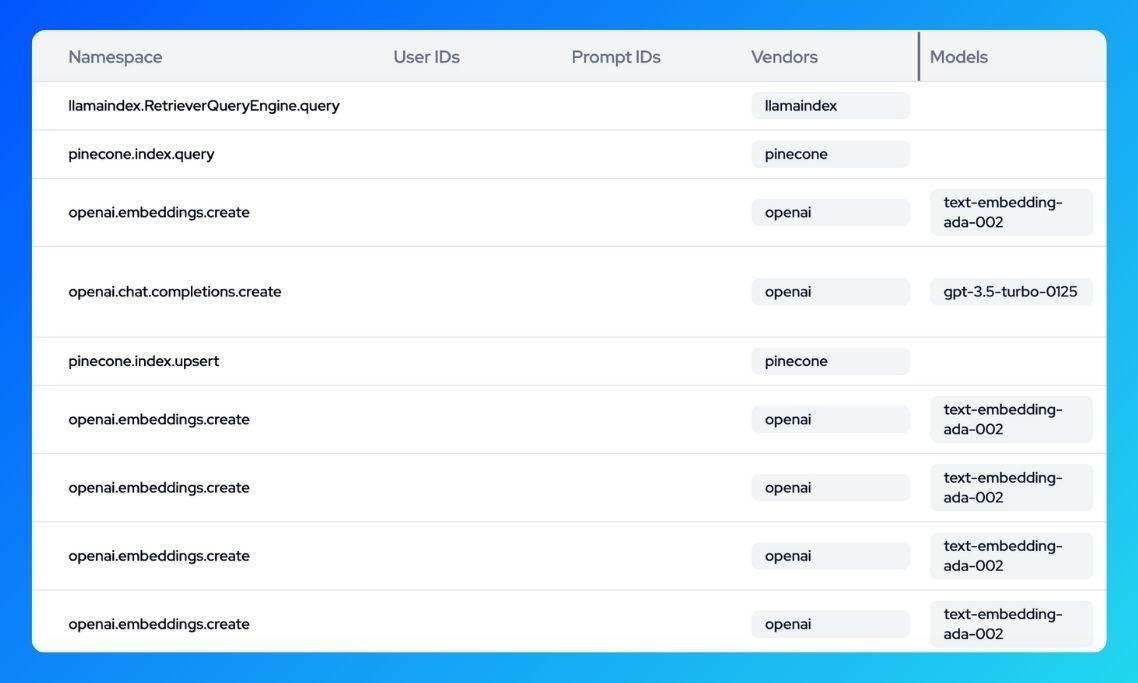
We can see traces for a number of embeddings being created and that's because LlamaIndex splits the initial document into chunks and converts each chunk into an embedding using OpenAI's text-embedding-ada-002 model. We can also see the pinecone.index.upsert action which is how the embeddings are stored in Pinecone.
Looking at the most trace, we can see that the llamaindex.RetrieverQueryEngine.query, which happens when we run query_engine.query("What's the price of the Quesadillas at Crepawayre?"), executes three different actions: converts the query into embeddings, queries Pinecone to get the relevant data based on the query, and finally sends the query to the LLM (OpenAI). We can also see the duration of the trace as well as the duration of the individual spans that make up that trace.
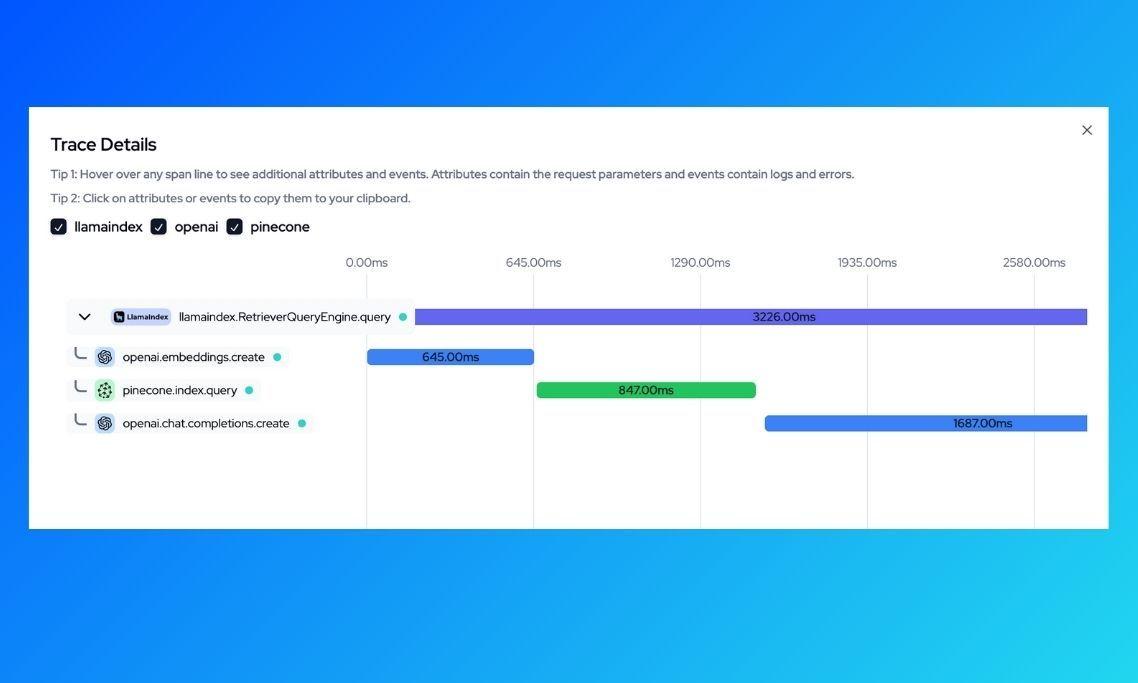
With this breakdown, we can go further to have a look at exactly what happens in each of these spans by clicking on it. Lets see the exact query that's sent to OpenAI (we expect this to be augmented with relevant context based on the initial query What's the price of the Quesadillas at Crepawayre?)
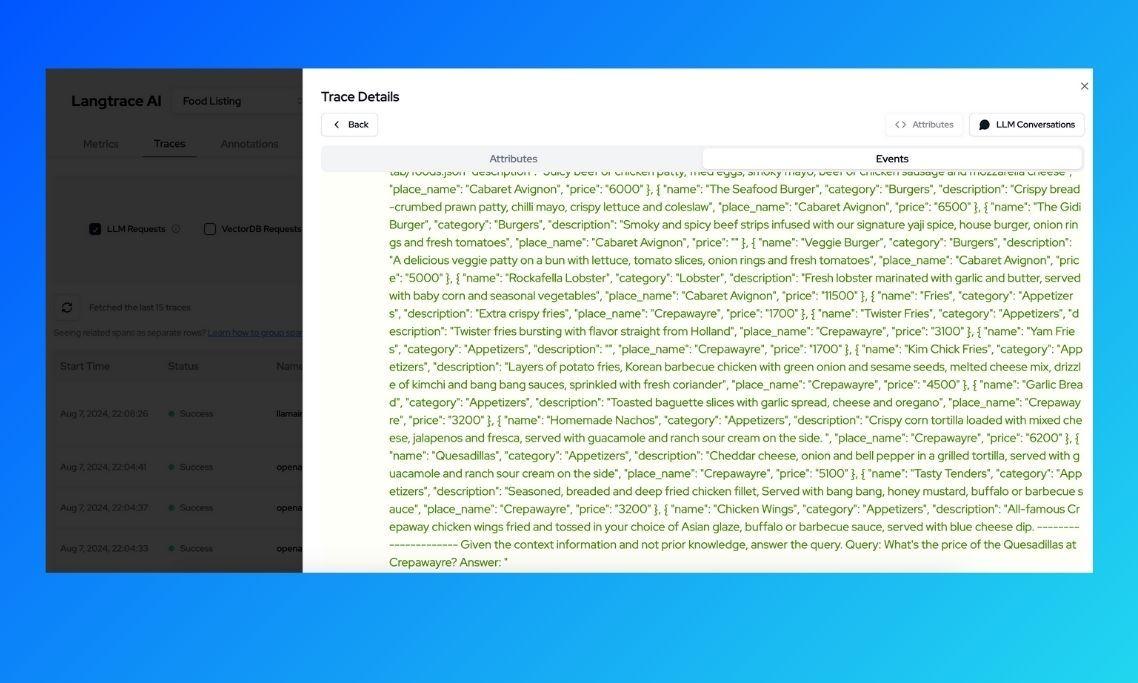
We can see that the query is appended to the a list of items returned from the vector search (in this case, all the food items with place_name set to Crepawayre) and this is what is sent to OpenAI chat completions API. With the query and relevant context, OpenAI is able to return a correct response.
For subsequent queries, because the embeddings are already stored in Pinecone, all we need to do is use the index to query those embeddings to get the relevant context we need to query the LLM. Also these queries will run a lot faster because indexing and inserting the embeddings into Pinecone only needs to happen once (except we're adding more data or creating a new index).
Conclusion
As powerful as LLMs are, they are somewhat limited to the data they are trained on. While LLMs are very useful in responding to general prompts quickly, they often fall short when users seek a deeper dive into current or more specific topics. This limitation highlights the need for Retrieval-Augmented Generation (RAG), which leverages data fetched from external sources. By integrating RAG, we can enhance the capabilities of LLMs, providing users with more accurate and up-to-date responses tailored to their specific needs.
In this post, we covered how to implement a standard RAG system using LlamaIndex, Pinecone and OpenAI. We also used Langtrace to monitor the performance of each of these components and how they work together. Also, you can choose to go a different route e.g. using a different LLM like Anthropic instead of OpenAI or a different vector database like Weaviate in place of Pinecone. LlamaIndex, as well as Langtrace, has integrations for a number of LLMs, frameworks, and vector stores thereby making customization seamless.
Useful Resources
Getting started with LlamaIndex https://docs.llamaindex.ai/en/stable/
LlamaIndex vector stores https://docs.llamaindex.ai/en/stable/module_guides/storing/vector_stores/
Getting started with Pinecone https://docs.pinecone.io/guides/get-started/quickstart
Getting started with Langtrace https://docs.langtrace.ai/introduction
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
