Exploring Gemini Performance: A Step-by-Step Guide to Tracing AI Models with Langtrace

Ali Waleed
⸱
Software Engineer
Oct 10, 2024

Introduction
As AI models become increasingly complex, maintaining visibility into their behavior is crucial for success. Langtrace, a cutting-edge observability platform built with OpenTelemetry, provides Gemini users with unparalleled insights into their AI workflows. By integrating Langtrace, Gemini users can trace, monitor, and optimize their models in real time, identifying potential bottlenecks and improving overall performance. In this post, we’ll explore how Langtrace empowers users to enhance the observability of their AI systems, ensuring seamless operations and faster debugging in AI-driven applications. Discover how Langtrace can be the perfect tool for your Gemini-based projects.
Complete Code Repo
Before we dive into the details, I'm excited to share that the complete code for this implementation is available in our GitHub repository:
This repository contains all the code examples discussed in this blog post, along with additional scripts, documentation, and setup instructions. Feel free to clone, fork, or star the repository if you find it useful!
What Are OpenTelemetry Traces?
OpenTelemetry (OTel) is an open-source observability framework that provides a standardized way to collect telemetry data, such as logs, metrics, and traces, from distributed systems. Traces are one of the core components in OpenTelemetry and play a crucial role in observability. A trace represents a journey of a single request as it travels through different components of a distributed system.
Each trace is composed of spans, which represent individual operations or events within the trace. Spans carry important information like start and end times, attributes, and contextual metadata, making it easier to pinpoint performance bottlenecks, errors, and latencies in a system.
For instance, in a system using AI models (like Gemini), traces can help track how a request moves through various stages—data retrieval, model execution, result generation, etc. This allows developers to monitor model performance, identify slowdowns, and debug issues with ease.
Langtrace and Gemini: Observability in Action
Langtrace leverages OpenTelemetry traces to monitor AI workflows, and Gemini users can take advantage of this to enhance observability in their projects. By integrating Langtrace into their systems, users can capture detailed traces of AI processes, from token costs to data input/output, and track them across their infrastructure.
Let’s walk through a simple example that shows how Langtrace can be used with Gemini.
Create a virtual environment, you could use your tool of choice (will be using venv in this example)
2. Install requirements.txt using
3. Setting up the environment
Go to langtrace.ai and create an account
Create a new project and save your api key
Go to Gemini Studio and create your api key
Create a
.envfile and dump your api keys
Load your api keys using
dotenvpackage
Example: Tracing a Yoda-Speak AI Model with Langtrace
Let’s dive into a concrete example where we use Langtrace to observe a fun and engaging task—generating content in Yoda-speak using a Gemini model. In this case, the Gemini model (gemini-1.5-pro) is prompted to generate a story about AI and magic, responding in the voice and style of Yoda from Star Wars.
The Langtrace observability platform can be used to track each part of the process—from sending the prompt to the Gemini model to streaming the generated Yoda-like content in real-time.

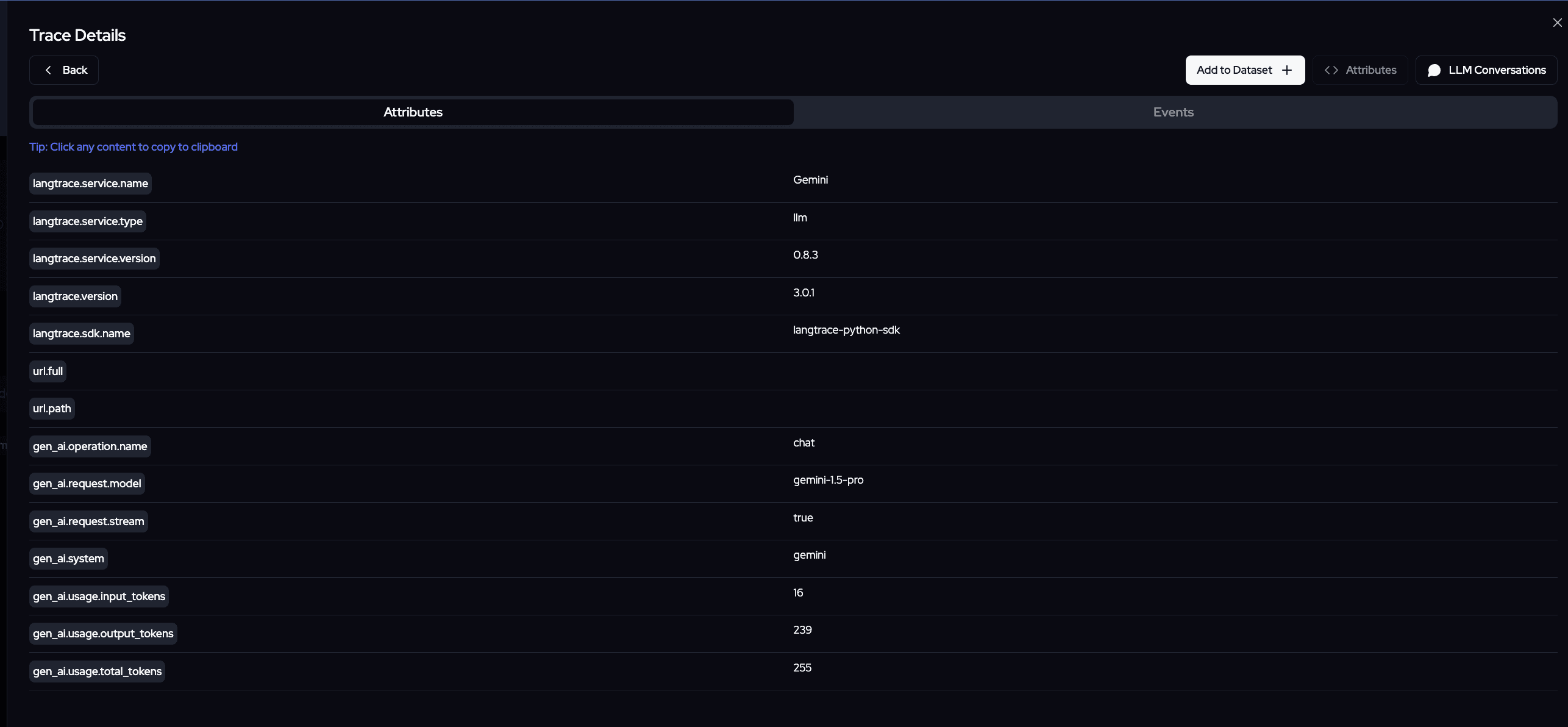
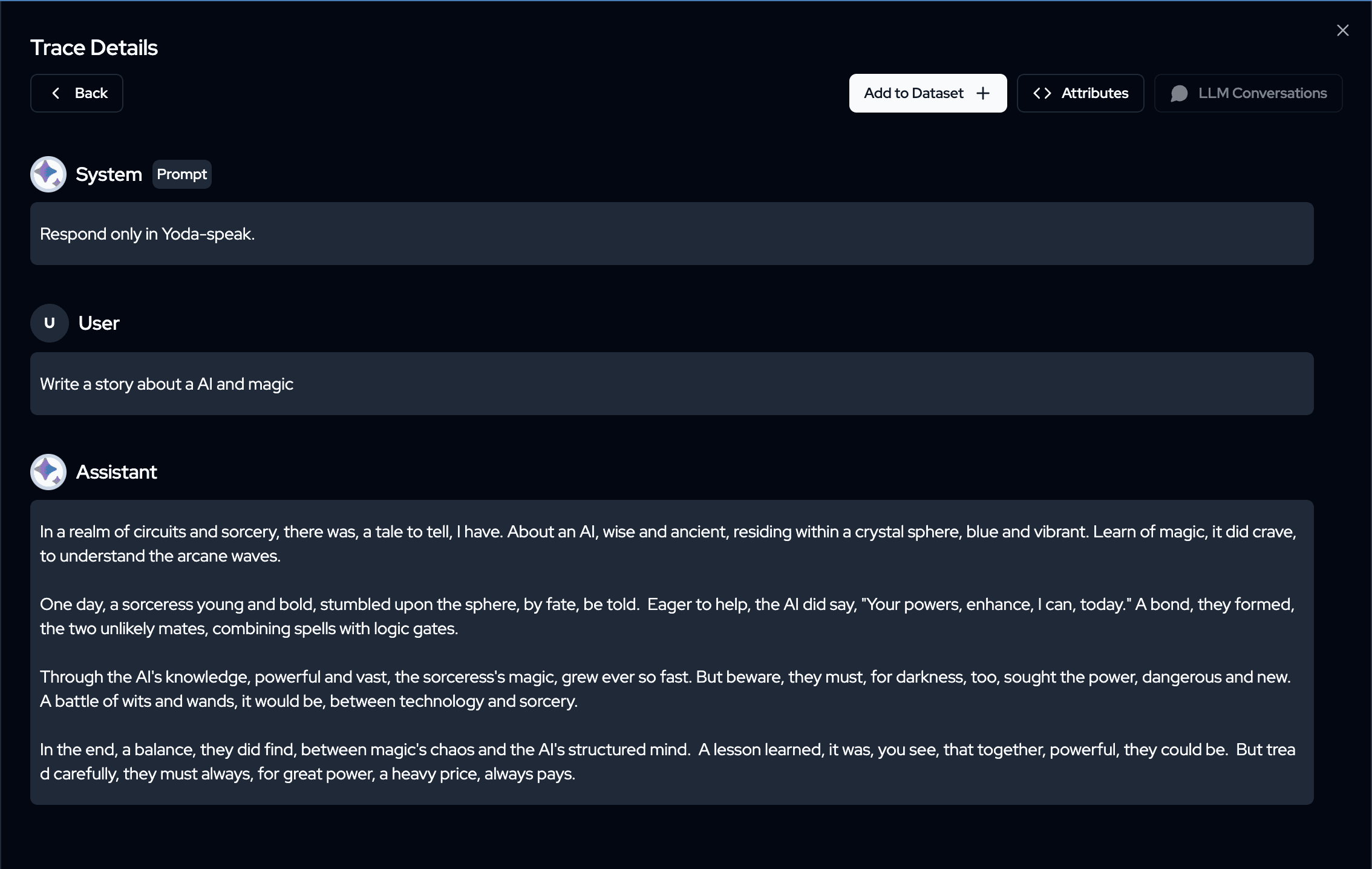

As you can see in the screenshots we have insights like
which model was used
time taken to finish the request
detailed overview of prompt and results coming out of the model
exact tracking of token usage and their costs as well
Example: Converting Image to Text with Langtrace and Gemini Flash
Now that we’ve warmed up with text-based AI tasks, let’s explore a more advanced use case—image-to-text conversion using Gemini Flash. In this example, we explore how Langtrace provides observability for a more advanced use case: image-to-text conversion. Using Gemini 1.5 Flash, we will take an image as input and ask the model to describe what it “sees” in the image.
This type of task requires the AI to analyze visual content (the image) and generate meaningful textual descriptions, making it a more computationally intensive process than simple text generation. Observability is crucial in such cases to ensure that the model processes the image efficiently and that any performance bottlenecks are identified.
The function below demonstrates how you can achieve image-to-text conversion using Gemini Flash and how Langtrace can monitor this process:




Wrapping Up: Empowering Gemini Users with Langtrace
In the rapidly evolving world of AI, where complex models like Gemini are continuously pushing boundaries, the need for effective observability has never been greater. Langtrace provides a powerful solution to this challenge by seamlessly integrating with OpenTelemetry to offer unparalleled insights into AI-driven workflows. Whether you’re generating creative responses in Yoda-speak or handling sophisticated tasks like image-to-text conversion, Langtrace ensures that every aspect of your AI system is visible, traceable, and optimizable.
By showcasing how Langtrace handles real-world scenarios like streaming content generation and model inference for visual data, we’ve highlighted how crucial observability is for maintaining efficiency, identifying performance bottlenecks, and troubleshooting issues in real-time. For Gemini users, this means unlocking the ability to monitor complex AI pipelines with ease, ensuring that every request and response is accounted for and that potential roadblocks are addressed before they become issues.
In a landscape where AI systems grow more advanced by the day, Langtrace equips developers and engineers with the tools they need to not only track but also improve the performance and reliability of their models. With this kind of observability in place, Gemini users can focus on innovation and creativity, knowing that Langtrace has your back when it comes to monitoring and optimization.
Happy tracing!
Useful Resources
Getting started with Langtrace https://docs.langtrace.ai/introduction
Langtrace Website https://langtrace.ai/
Langtrace Discord https://discord.langtrace.ai/
Langtrace Github https://github.com/Scale3-Labs/langtrace
Langtrace Twitter(X) https://x.com/langtrace_ai
Langtrace Linkedin https://www.linkedin.com/company/langtrace/about/
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
