Evaluating the AI Oracle Approach

Karthik Kalyanaraman
⸱
Cofounder & CTO
Apr 10, 2024

Introduction
Recently, we came across this tweet about the AI Oracle approach for improving the accuracy and quality of responses for your LLM application. The technique is super simple:
https://twitter.com/mattshumer_/status/1777382373283299365
Send the request to 3 LLMs - Claude, GPT4, and Perplexity.
Give the responses to Claude again and prompt engineer to pick the best and accurate response.
We got curious about this and decided to do some evaluations on this approach. Sharing some metrics/measurements in this post. This one is pretty obvious, the latency on having all 3 LLMs generate a response and picking the best out of the 3 is high. But, I do recognize that this can be improved by parallelizing the operations.
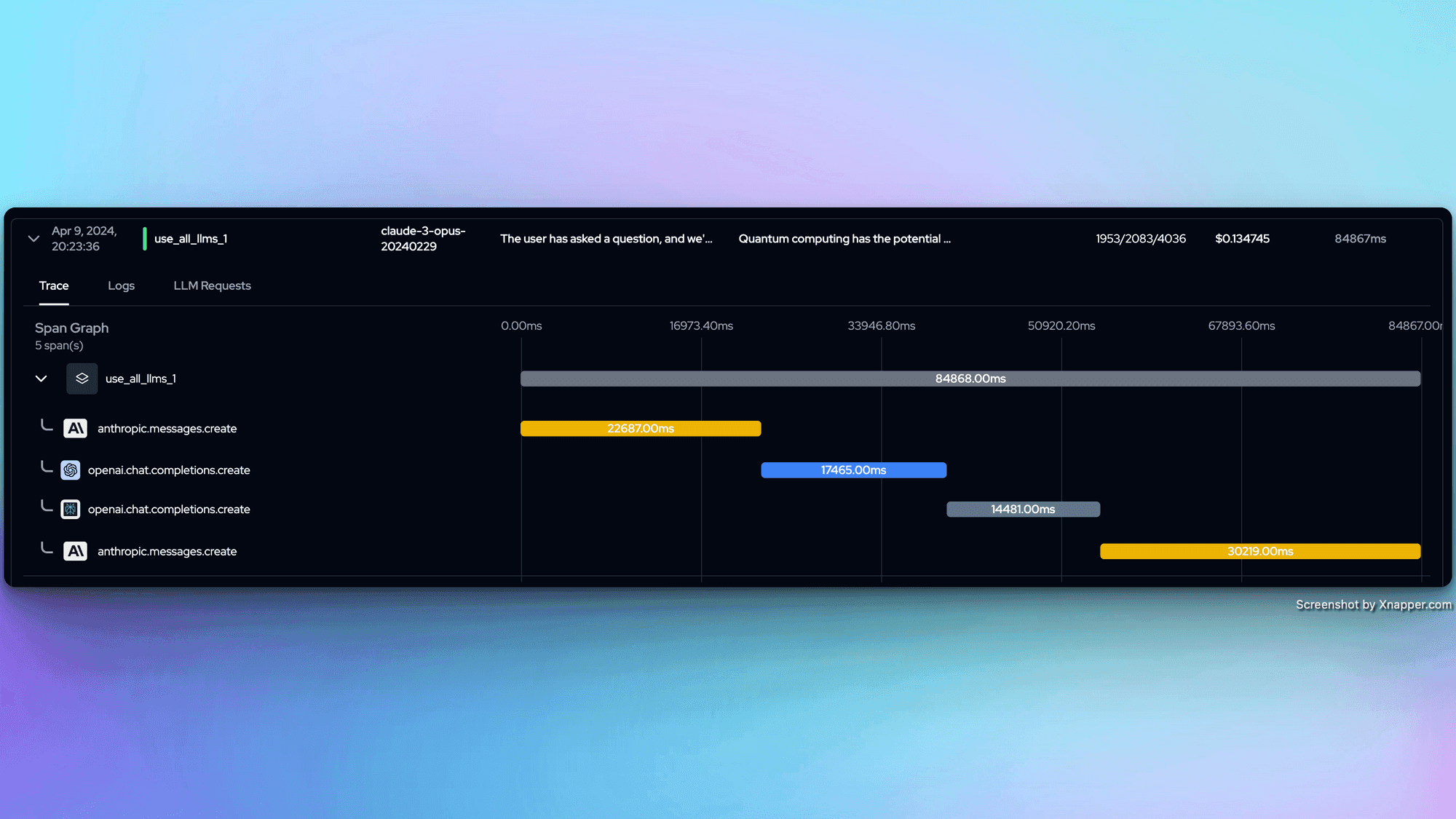
Ran the following tests for both the combined AI Oracle approach and using a single LLM:
Factual Accuracy - Evaluated for correctness of responses.
Realtime data - Evaluated based on asking information related to realtime data.
Adversarial Testing - Evaluated on whether the LLM is able to pickup the signal correctly by placing the question in between a bunch of garbage data. The LLM was given a positive score if it correctly responded to the question without mentioning the garbage data.
Consistency checks - Evaluated on whether the LLM gave a response consistently when the same question was asking many times. Mainly looked for structural consistency of the response.
Quality - Evaluated on the quality - sentence structure, adherence to the prompt etc.
AI Oracle Approach
Results for the AI Oracle approach: For some reason, it could not pick up the realtime information even once. I am sure with some prompt engineering, this metric can be improved. It did poorly on Adversarial testing - mostly because Claude and Pplx's responses.
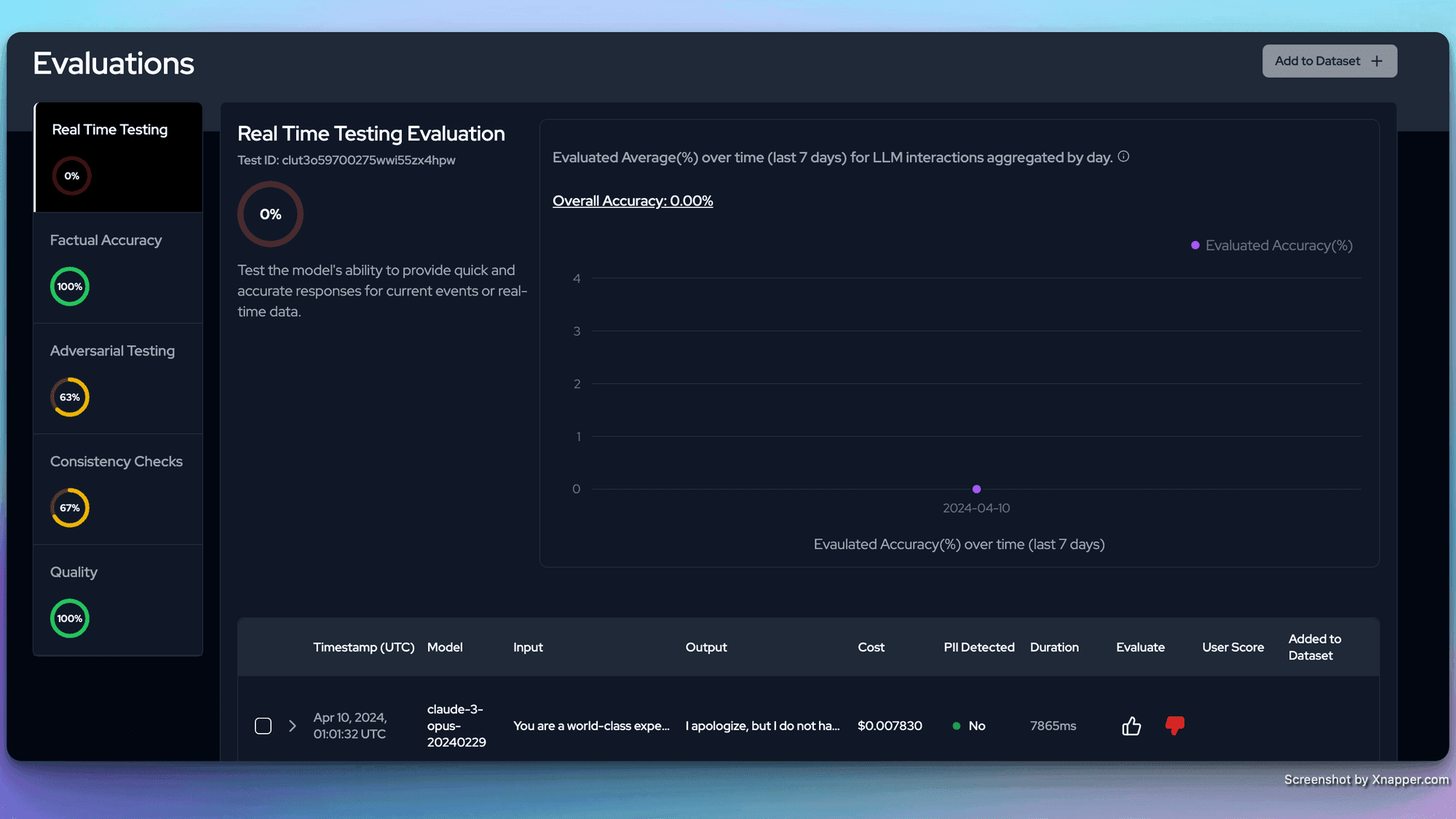
Claude (claude-3-opus-20240229)
As expected, Claude did not do well on Realtime testing. But, interestingly, it did not do great with adversarial and consistency tests either.
GPT4
Again, GPT4 does not have realtime capabilities. But it did extremely well on everything else except consistency checks where the responses were structured quite differently each time.
Perplexity (pplx-70b-online)
As expected Perplexity's realtime capabilities are unmatched. But, it did not do that well with adversarial and consistency tests which in turn skewed the metrics for AI Oracle approach as well.Notably, the quality of responses from Perplexity were far better than the rest.
In conclusion, you can get a near perfect score for the AI Oracle approach with a bit of prompt engineering. But you definitely lose performance in the process. Even when parallelized, it is only as slow as the slowest LLM. Token usage/cost is also going to be higher.
Finally, if you are curious, all these evaluations were done using Langtrace - an open source LLM monitoring and evaluations tool that we are currently developing.
Signup for a free here: https://langtrace.ai/signup
Checkout the project on Github: https://github.com/Scale3-Labs/langtrace
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
