Evaluating a RAG Agent using Langtrace

Karthik Kalyanaraman
⸱
Cofounder and CTO
Mar 27, 2025

Introduction
In this post, we’ll walk through how to build a simple Retrieval-Augmented Generation (RAG) agent using Agno and Weaviate, and how to trace and evaluate its performance using Langtrace.
Setup
We start by setting up our environment. First, we import necessary libraries and initialize our tracing with Langtrace.
For this, we will be using the simple RAG example from Agno's docs under Weaviate.
The knowledge base PDF is all about Thai curry recipes. Once the agent is set up, we can execute it and retrieve responses.
Tracing and Evaluation
Once the agent starts running, we can observe traces generated by Langtrace. These traces provide insights into various aspects of the agent's interactions, from tool calls to the execution times of individual components.
We’ll use the Langtrace interface to track traces and dive deeper into the Human Evaluations tab to evaluate the agent’s performance across different metrics. These include:
LLM Metrics: Model Accuracy, Query Relevance, Tool Suggestion
VectorDB Metrics: Retrieval Accuracy
All of these metrics are evaluated on a binary scale (pass/fail) for simplicity.

Categories of Evaluation
Langtrace allows us to categorize the evaluations into three distinct layers: LLM, VectorDB, and Framework. This is especially useful for RAG systems, where performance can be affected by multiple components. By categorizing the evaluations, you can identify and optimize specific areas, ensuring that the system performs well overall.
Manual Evaluation
With the traces in place, we go through each trace and manually evaluate the appropriate layer (span) to get a better understanding of the performance. Each evaluation helps us to fine-tune the system, ensuring high accuracy across the board.

Scoring and Confidence
Langtrace calculates the overall scores for each metric, showing both the median and average scores. The confidence score reflects the reliability of the evaluation. The more traces we evaluate, the higher the confidence in the results.
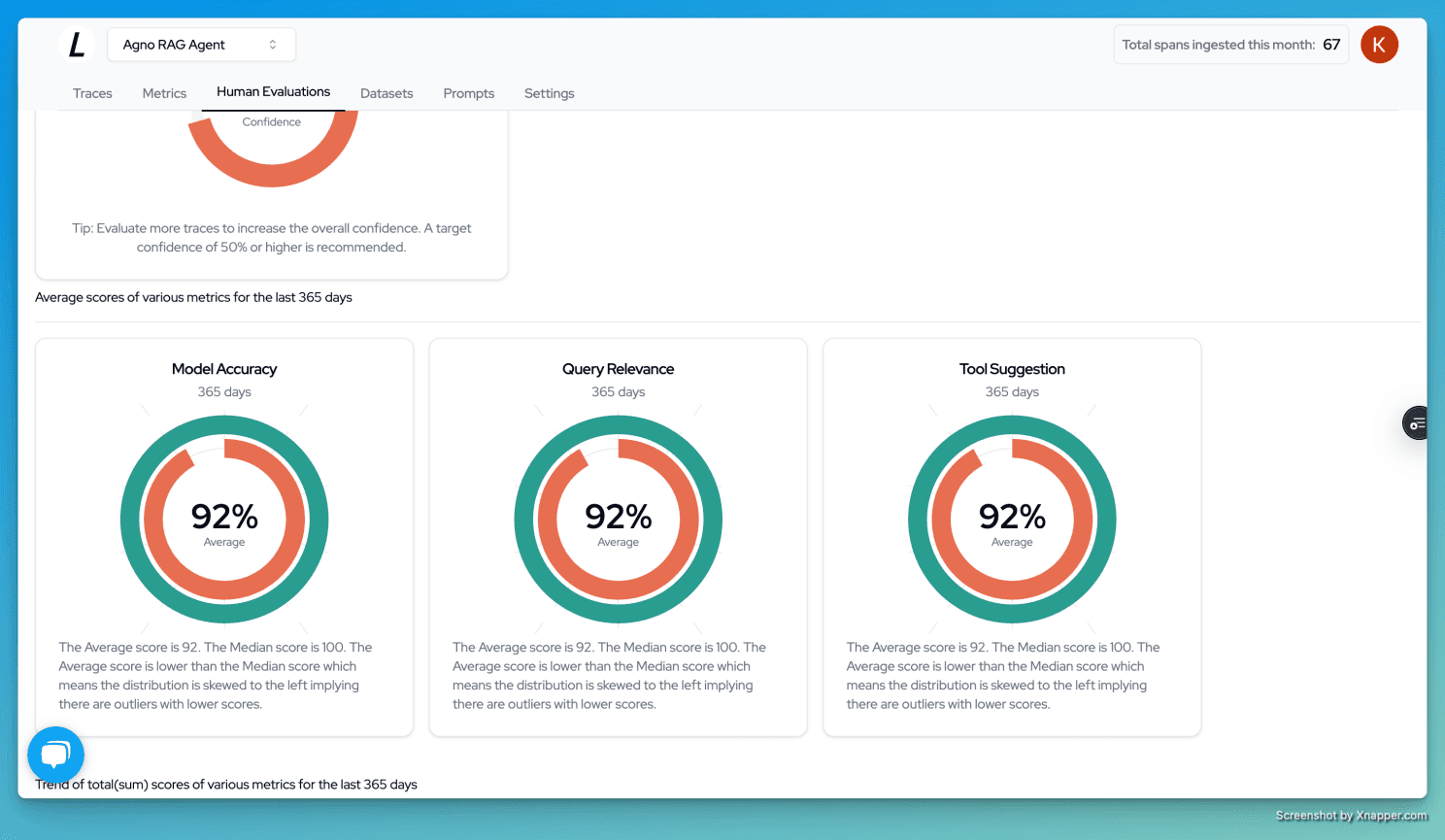
Conclusion
In conclusion, using Langtrace with Agno and Weaviate for building and evaluating RAG agents provides a robust solution for tracking performance and pinpointing areas for improvement. The detailed trace information, combined with structured human evaluations, offers a comprehensive view of the system’s performance, helping developers optimize their models and vector databases more effectively.
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
