Enhancing Vector Database Observability: Langtrace x Milvus Integration

Ali Waleed
⸱
Software Engineer
Nov 19, 2024

Introduction
In the era of AI-driven applications, vector databases like Milvus are powering next-generation search engines, recommendation systems, and data retrieval solutions. But with great power comes great complexity. As these systems handle high-dimensional vectors and large-scale queries, observability becomes a critical need—not just for troubleshooting but for optimizing performance and ensuring seamless user experiences.
This is where Langtrace steps in, offering deep observability for Milvus’s workflows. From collection creation to vector searches, Langtrace provides the insights developers need to monitor, debug, and optimize every step of their pipeline. In this guide, we’ll explore how Langtrace integrates with Milvus, showcasing its capabilities through a step-by-step walkthrough of essential Milvus functions.
By the end, you’ll see how Langtrace x Milvus transforms your observability game, giving you full visibility into your vector database operations. Let’s dive in!
Why Observability in Vector Databases is Important
As machine learning and AI systems continue to evolve, vector databases like Milvus have become indispensable for managing high-dimensional data. Whether you’re building image recognition systems, recommendation engines, or semantic search tools, vector DBs provide the backbone for storing and retrieving embeddings efficiently.
But with this power comes complexity. Vector searches involve intricate computations like similarity scoring, approximate nearest neighbor (ANN) algorithms, and indexing optimizations. Without proper observability, issues such as slow query performance, indexing errors, or misaligned embeddings can be hard to diagnose and fix.
This is why observability in vector databases is not just a luxury—it’s a necessity:
• Debugging Made Easy: Trace errors back to their root cause, whether they stem from embedding quality or database configuration.
• Performance Optimization: Monitor query latencies, index build times, and other metrics to fine-tune performance.
• Workflow Insights: Gain a comprehensive view of how your data flows through the pipeline—from collection creation to vector retrieval.
Langtrace bridges this gap by bringing OpenTelemetry-powered observability to Milvus. It tracks each stage of your database workflow, providing actionable insights through spans, metrics, and events. Let’s explore this integration step by step, starting with the basics of collection creation.
Step-by-Step Guide: Langtrace x Milvus Integration in Action
In this section, we’ll walk through the key functions of Milvus while showcasing how Langtrace enhances observability at each step. Along the way, we’ll include screenshots of the Langtrace dashboard and relevant code snippets to bring the integration to life.
Create a virtual enviroment
Install
Pymilvus&LangtraceInitialize
Pymilvusclient &LangtraceCreate Collection
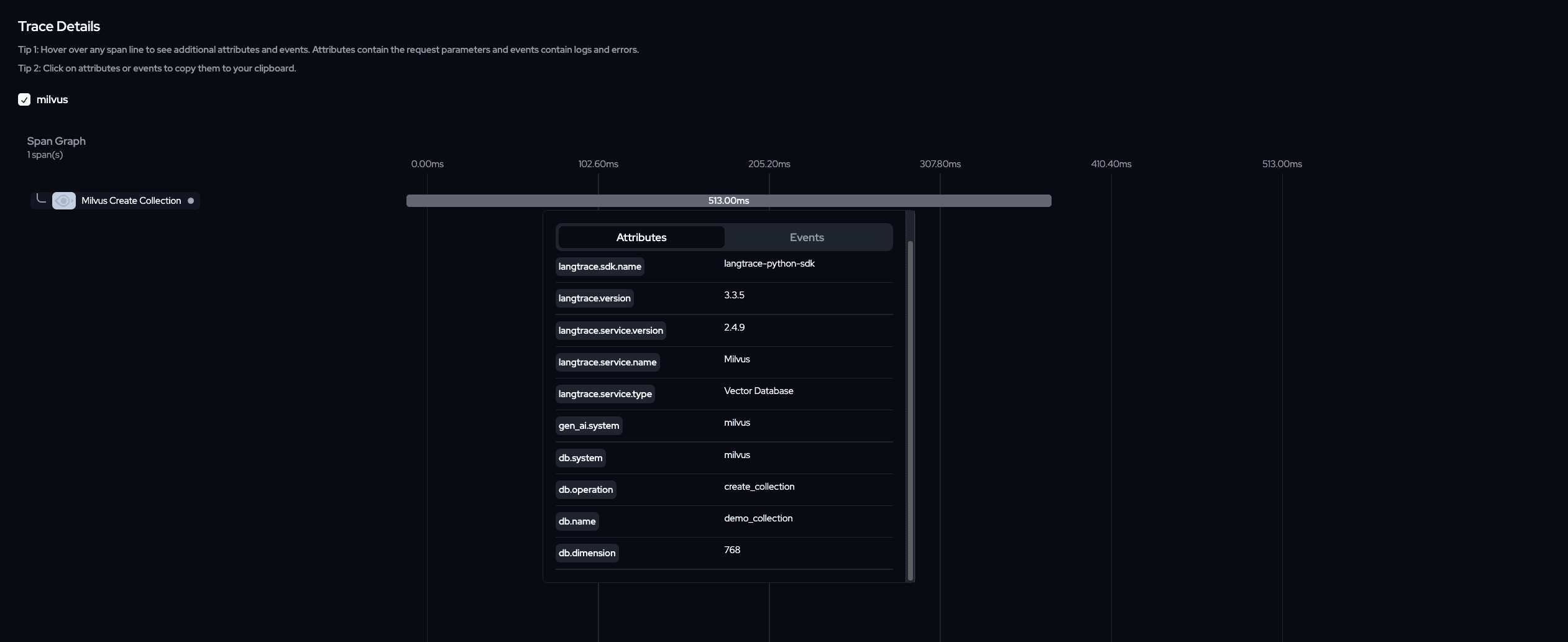
Create an embedding helper
Insert Data
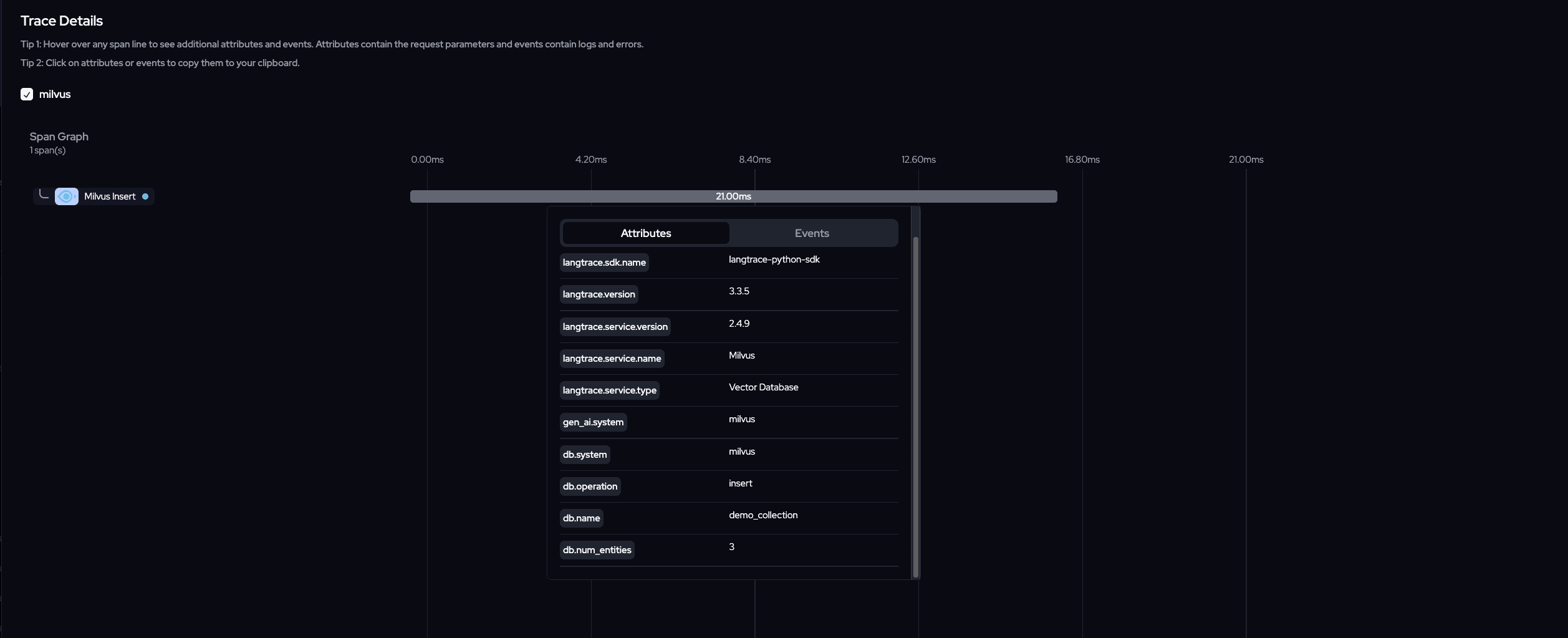
Query data
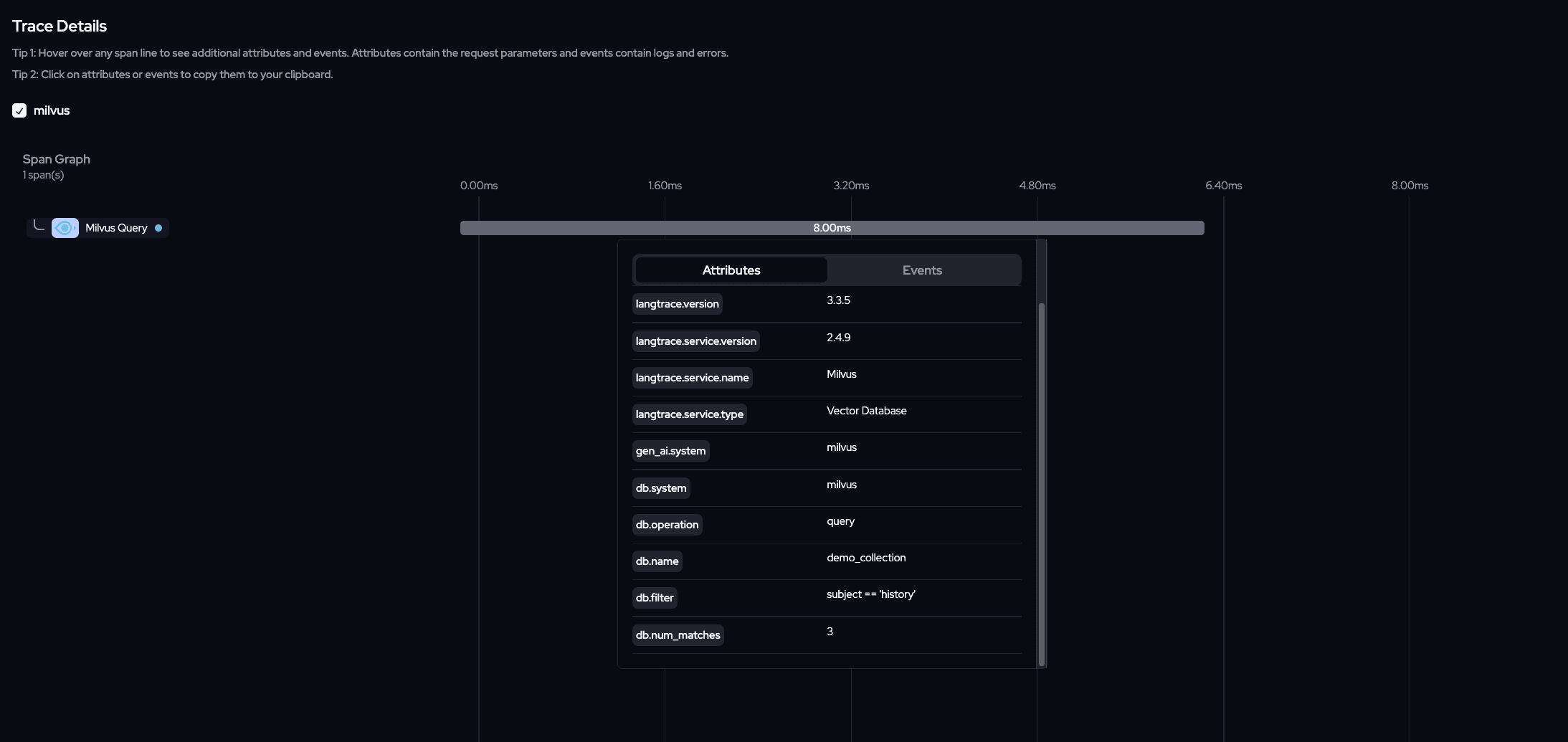
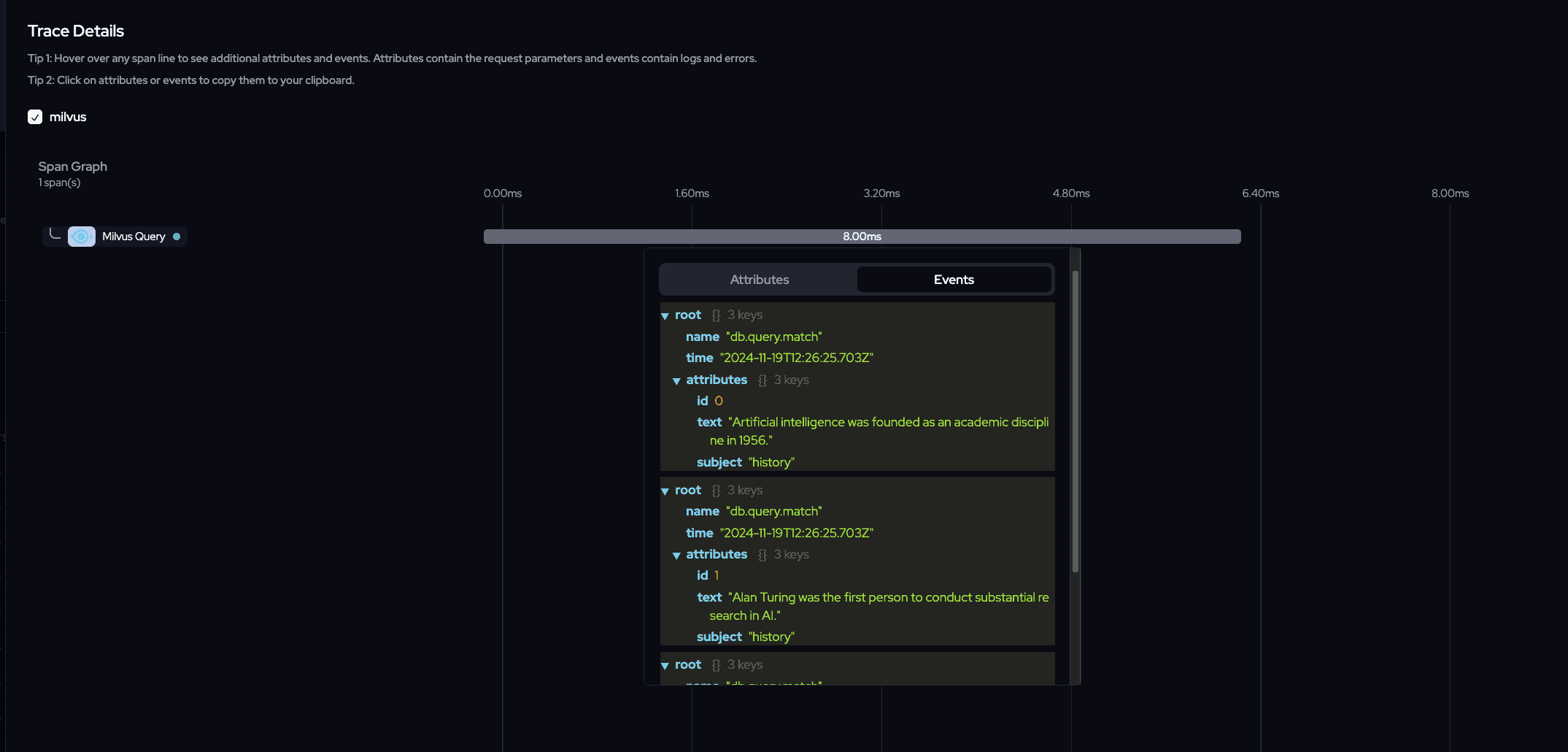
Vector Search
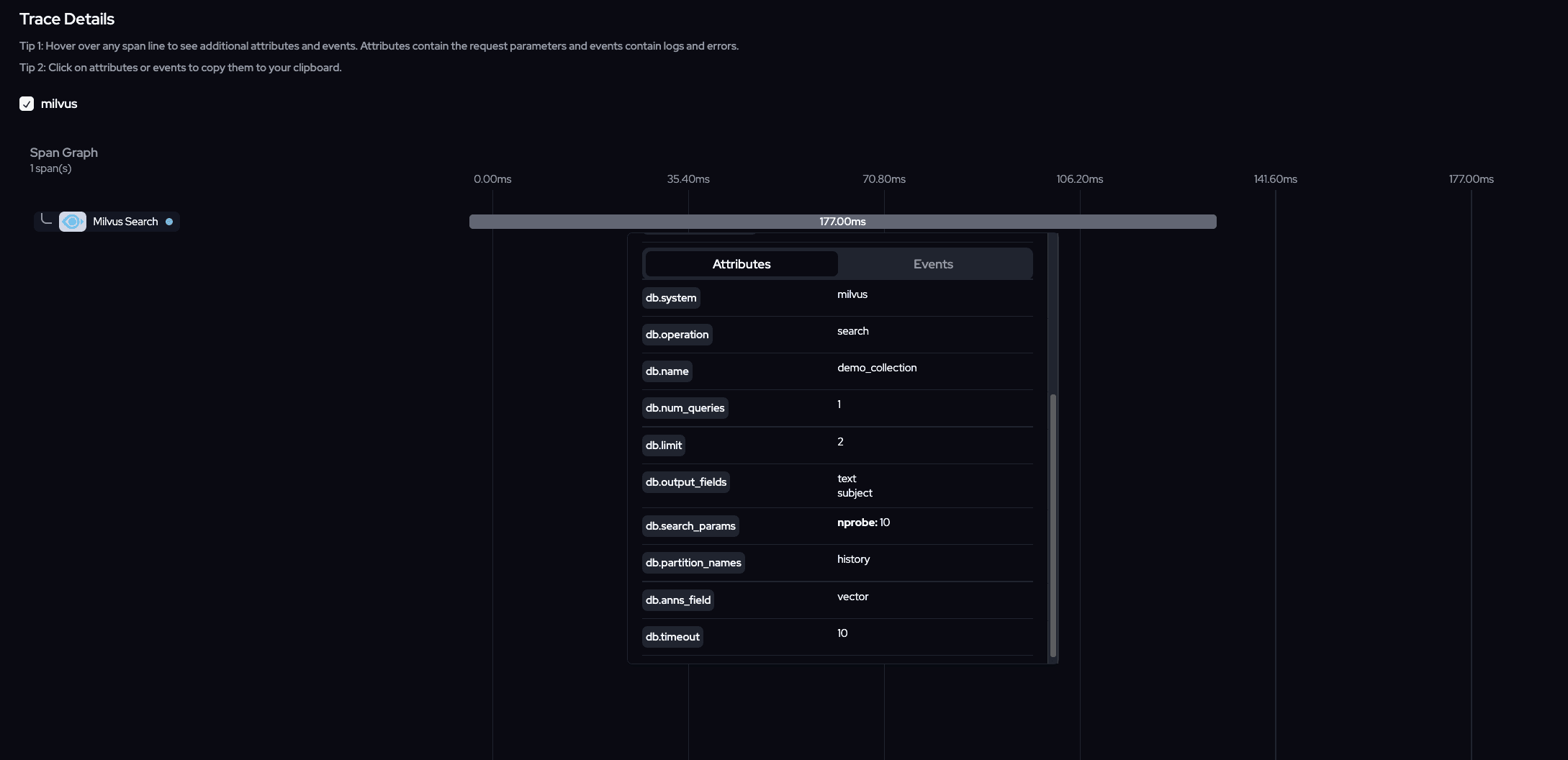
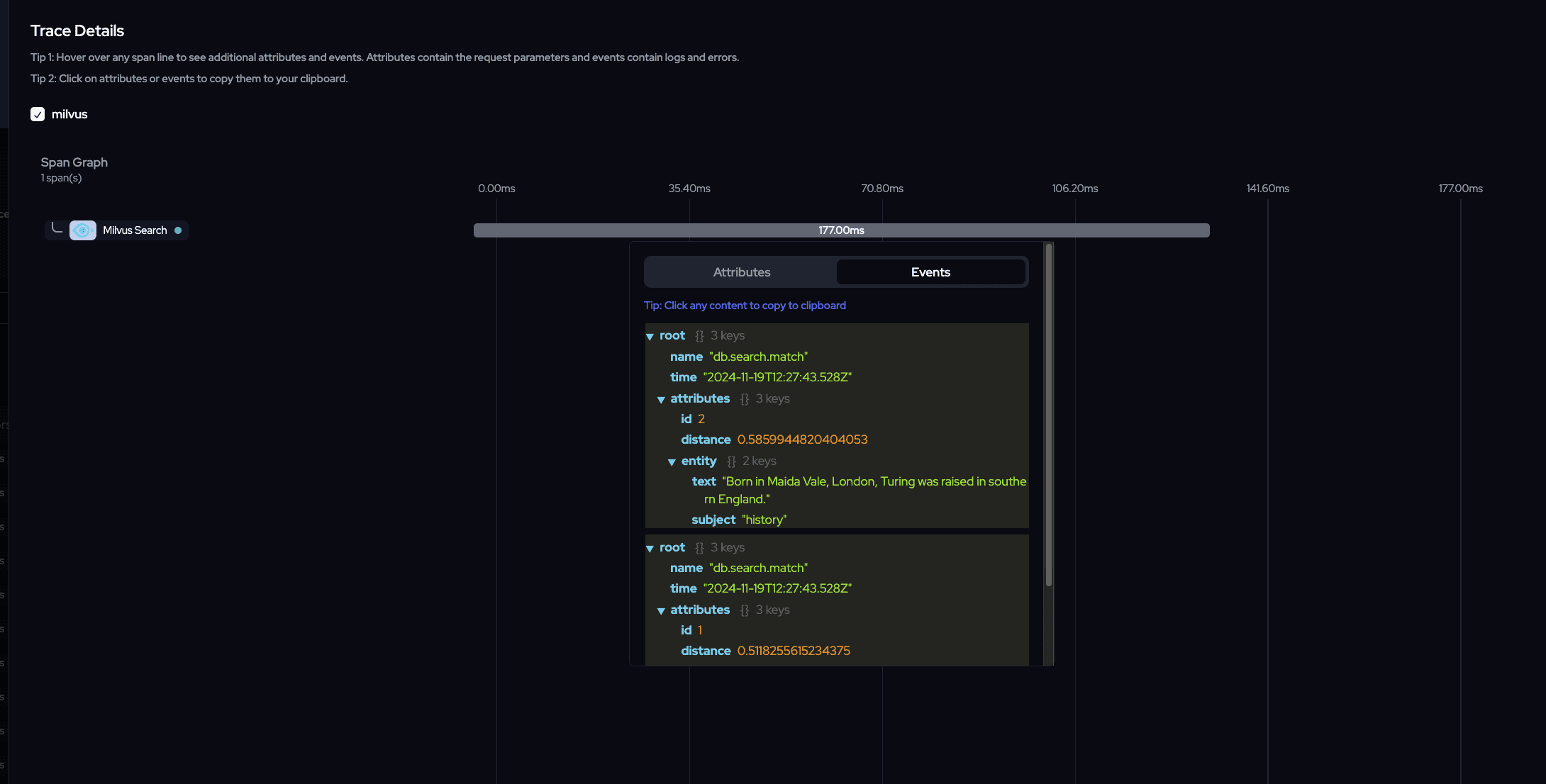
Now let's observe the full trace for the whole pipeline
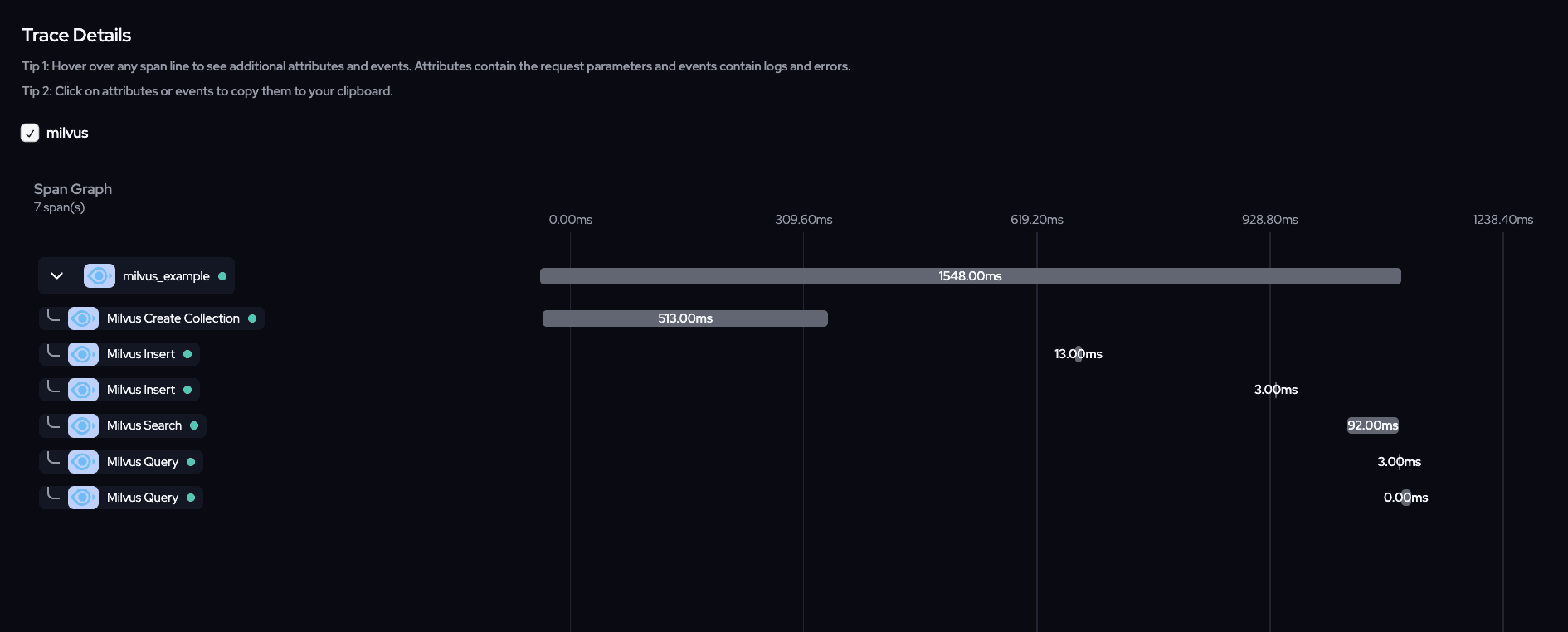
Conclusion
The integration of Langtrace with Milvus unlocks a powerful combination of vector database performance and deep observability. By tracing each operation—from collection creation to vector search—you gain unparalleled visibility into your data workflows. With this setup, you can debug faster, optimize query performance, and ensure your applications run seamlessly.
Whether you’re building AI-powered search engines, recommendation systems, or knowledge graphs, the ability to monitor and optimize your database workflows is no longer optional—it’s essential. Langtrace not only bridges this gap but also empowers you to focus on innovation while it handles the complexities of observability.
Ready to elevate your Milvus workflows? Start exploring Langtrace x Milvus today, and take your vector database observability to the next level. 🚀
Useful Resources
Getting started with Langtrace https://docs.langtrace.ai/introduction
Langtrace Github https://github.com/Scale3-Labs/langtrace
Langtrace Website https://langtrace.ai/
Langtrace Discord https://discord.langtrace.ai/
Langtrace Twitter(X) https://x.com/langtrace_ai
Langtrace Linkedin https://www.linkedin.com/company/langtrace/about/

Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
