Build a reliable Summarization system using DSPy and Langtrace

Karthik Kalyanaraman
⸱
Cofounder and CTO
Oct 12, 2024

Introduction
Summarization is a fundamental task in natural language processing that involves condensing a longer piece of text into a shorter version while retaining its key information and main ideas. It's a crucial skill for both humans and machines, with applications ranging from creating article abstracts to generating concise reports from lengthy documents.
While summarization is valuable, evaluating the quality of summaries produced by language models presents significant challenges. Unlike tasks with clear right or wrong answers, summarization quality is often subjective and context-dependent. Some key difficulties in evaluating summarized outputs include:
Balancing information retention with conciseness
Preserving the original text's tone and intent
Ensuring factual accuracy without introducing errors
Adapting to different types of source material and summary purposes
Accounting for varying reader preferences and background knowledge
These challenges make it difficult to create universal metrics for summary quality, often requiring a combination of automated measures and human judgment for comprehensive evaluation.
In this example, we show how you can build a summarization system using DSPy. The technique involves the following:
We build a DSPy program for doing the actual summarization task which takes a `passage` as input and gives a `summary` as output.
We would ideally want to optimize the summarization program over a metric in order to build an effective program. But since writing a metric function for summarization tasks is subjective and ambiguous in nature, we can use a LM to do this task which in turn means we can write another DSPy program to do the task of scoring a summary based on the variable we care about.
Finally, we compose the system by using the Metric program for defining the metric function in the Summarization program.
Metric Program
Define two signatures for scoring the summary.
The first signature breaks down the summary and assigns defined labels as grades.
The second signature assigns a binary score using the summary and the break down from the previous signature as inputs
Now write the actual program that computes a weighted score between 0 to 1 and falls back to the overall_score that's loosely scored by the model
Summarization Program
First define it's signature
Next, define the program
Run and Evaluate
Let's jump into the actual process of running it and evaluating the pipeline.
First, setup and initialize Langtrace
Next, define the language model.
Load a dataset. The dataset is a `jsonl` file where each line has a passage, summary and a score.
Now, define the metric. This is where we use the `Metric` program to compute the score for the summary generated by the `Summarization` program.
Create the program and evaluate it.
You can debug and further optimize your program by looking into the traces on Langtrace.
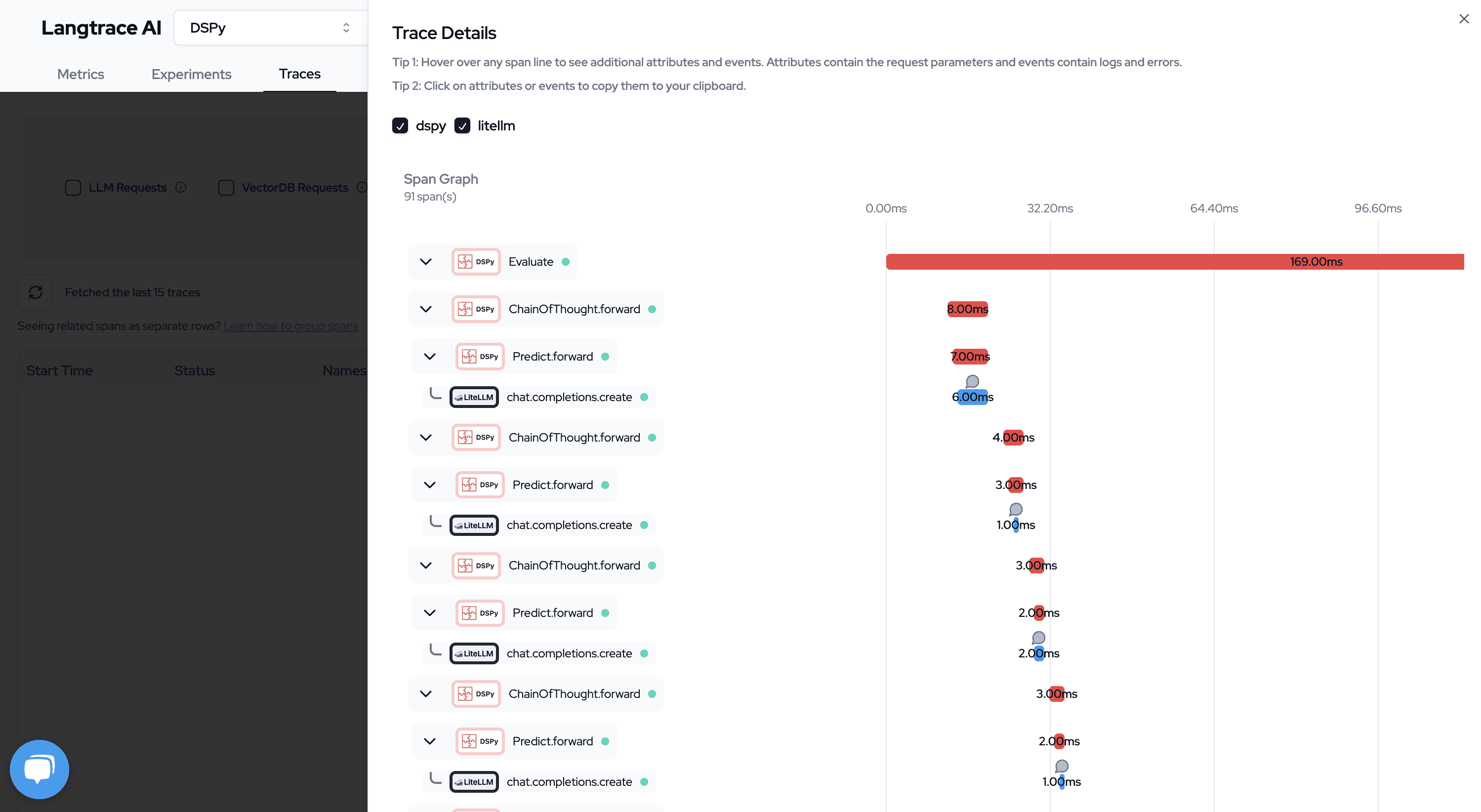
That's it! Hopefully this example was helpful in understanding how you can compose DSPy programs to build a truly compound AI system that's optimized for isolated tasks.
Useful Resources
Getting started with Langtrace https://docs.langtrace.ai/introduction
Langtrace Website https://langtrace.ai/
Langtrace Discord https://discord.langtrace.ai/
Langtrace Github https://github.com/Scale3-Labs/langtrace
Langtrace Twitter(X) https://x.com/langtrace_ai
Langtrace Linkedin https://www.linkedin.com/company/langtrace/about/
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
